基础版
DDL:创建和删除表
DML:增删改查
DCL:事务权限相关
事务:TCL
创建和管理表
SELECT *
FROM `order`;
#1. 创建和管理数据库
#1.1 如何创建数据库
#方式1:
CREATE DATABASE mytest1; # 创建的此数据库使用的是默认的字符集
#查看创建数据库的结构
SHOW CREATE DATABASE mytest1;
#方式2:显式了指名了要创建的数据库的字符集
CREATE DATABASE mytest2 CHARACTER SET 'gbk';
#
SHOW CREATE DATABASE mytest2;
#方式3(推荐):如果要创建的数据库已经存在,则创建不成功,但不会报错。
CREATE DATABASE IF NOT EXISTS mytest2 CHARACTER SET 'utf8';
#如果要创建的数据库不存在,则创建成功
CREATE DATABASE IF NOT EXISTS mytest3 CHARACTER SET 'utf8';
SHOW DATABASES;
#1.2 管理数据库
#查看当前连接中的数据库都有哪些
SHOW DATABASES;
#切换数据库
USE atguigudb;
#查看当前数据库中保存的数据表
SHOW TABLES;
#查看当前使用的数据库
SELECT DATABASE() FROM DUAL;
#查看指定数据库下保存的数据表
SHOW TABLES FROM mysql;
#1.3 修改数据库
#更改数据库字符集
SHOW CREATE DATABASE mytest2;
ALTER DATABASE mytest2 CHARACTER SET 'utf8';
#1.4 删除数据库
#方式1:如果要删除的数据库存在,则删除成功。如果不存在,则报错
DROP DATABASE mytest1;
SHOW DATABASES;
#方式2:推荐。 如果要删除的数据库存在,则删除成功。如果不存在,则默默结束,不会报错。
DROP DATABASE IF EXISTS mytest1;
DROP DATABASE IF EXISTS mytest2;
#2. 如何创建数据表
USE atguigudb;
SHOW CREATE DATABASE atguigudb; #默认使用的是utf8
SHOW TABLES;
#方式1:"白手起家"的方式
CREATE TABLE IF NOT EXISTS myemp1( #需要用户具备创建表的权限。
id INT,
emp_name VARCHAR(15), #使用VARCHAR来定义字符串,必须在使用VARCHAR时指明其长度。
hire_date DATE
);
#查看表结构
DESC myemp1;
#查看创建表的语句结构
SHOW CREATE TABLE myemp1; #如果创建表时没有指明使用的字符集,则默认使用表所在的数据库的字符集。
#查看表数据
SELECT * FROM myemp1;
#方式2:基于现有的表,同时导入数据
CREATE TABLE myemp2
AS
SELECT employee_id,last_name,salary
FROM employees;
DESC myemp2;
DESC employees;
SELECT *
FROM myemp2;
#说明1:查询语句中字段的别名,可以作为新创建的表的字段的名称。
#说明2:此时的查询语句可以结构比较丰富,使用前面章节讲过的各种SELECT
CREATE TABLE myemp3
AS
SELECT e.employee_id emp_id,e.last_name lname,d.department_name
FROM employees e JOIN departments d
ON e.department_id = d.department_id;
SELECT *
FROM myemp3;
DESC myemp3;
#练习1:创建一个表employees_copy,实现对employees表的复制,包括表数据
CREATE TABLE employees_copy
AS
SELECT *
FROM employees;
SELECT * FROM employees_copy;
#练习2:创建一个表employees_blank,实现对employees表的复制,不包括表数据
CREATE TABLE employees_blank
AS
SELECT *
FROM employees
#where department_id > 10000;
WHERE 1 = 2; #山无陵,天地合,乃敢与君绝。
SELECT * FROM employees_blank;
#3. 修改表 --> ALTER TABLE
DESC myemp1;
# 3.1 添加一个字段
ALTER TABLE myemp1
ADD salary DOUBLE(10,2); #默认添加到表中的最后一个字段的位置
ALTER TABLE myemp1
ADD phone_number VARCHAR(20) FIRST;
ALTER TABLE myemp1
ADD email VARCHAR(45) AFTER emp_name;
# 3.2 修改一个字段:数据类型、长度、默认值(略)
ALTER TABLE myemp1
MODIFY emp_name VARCHAR(25) ;
ALTER TABLE myemp1
MODIFY emp_name VARCHAR(35) DEFAULT 'aaa';
# 3.3 重命名一个字段
ALTER TABLE myemp1
CHANGE salary monthly_salary DOUBLE(10,2);
ALTER TABLE myemp1
CHANGE email my_email VARCHAR(50);
# 3.4 删除一个字段
ALTER TABLE myemp1
DROP COLUMN my_email;
#4. 重命名表
#方式1:
RENAME TABLE myemp1
TO myemp11;
DESC myemp11;
#方式2:
ALTER TABLE myemp2
RENAME TO myemp12;
DESC myemp12;
#5. 删除表
#不光将表结构删除掉,同时表中的数据也删除掉,释放表空间
DROP TABLE IF EXISTS myemp2;
DROP TABLE IF EXISTS myemp12;
#6. 清空表
#清空表,表示清空表中的所有数据,但是表结构保留。
SELECT * FROM employees_copy;
TRUNCATE TABLE employees_copy;
SELECT * FROM employees_copy;
DESC employees_copy;
#7. DCL 中 COMMIT 和 ROLLBACK
# COMMIT:提交数据。一旦执行COMMIT,则数据就被永久的保存在了数据库中,意味着数据不可以回滚。
# ROLLBACK:回滚数据。一旦执行ROLLBACK,则可以实现数据的回滚。回滚到最近的一次COMMIT之后。
#8. 对比 TRUNCATE TABLE 和 DELETE FROM
# 相同点:都可以实现对表中所有数据的删除,同时保留表结构。
# 不同点:
# TRUNCATE TABLE:一旦执行此操作,表数据全部清除。同时,数据是不可以回滚的。
# DELETE FROM:一旦执行此操作,表数据可以全部清除(不带WHERE)。同时,数据是可以实现回滚的。
/*
9. DDL 和 DML 的说明
① DDL的操作一旦执行,就不可回滚。指令SET autocommit = FALSE对DDL操作失效。(因为在执行完DDL
操作之后,一定会执行一次COMMIT。而此COMMIT操作不受SET autocommit = FALSE影响的。)
② DML的操作默认情况,一旦执行,也是不可回滚的。但是,如果在执行DML之前,执行了
SET autocommit = FALSE,则执行的DML操作就可以实现回滚。
*/
# 演示:DELETE FROM
#1)
COMMIT;
#2)
SELECT *
FROM myemp3;
#3)
SET autocommit = FALSE;
#4)
DELETE FROM myemp3;
#5)
SELECT *
FROM myemp3;
#6)
ROLLBACK;
#7)
SELECT *
FROM myemp3;
# 演示:TRUNCATE TABLE
#1)
COMMIT;
#2)
SELECT *
FROM myemp3;
#3)
SET autocommit = FALSE;
#4)
TRUNCATE TABLE myemp3;
#5)
SELECT *
FROM myemp3;
#6)
ROLLBACK;
#7)
SELECT *
FROM myemp3;
#######################
#9.测试MySQL8.0的新特性:DDL的原子化,要么执行成功,要么回滚。
#以下命令book2表不存在,在8.0之前执行会删除book1表,在8.0执行会回滚book1
CREATE DATABASE mytest;
USE mytest;
CREATE TABLE book1(
book_id INT ,rr
book_name VARCHAR(255)
);
SHOW TABLES;
DROP TABLE book1,book2;
SHOW TABLES;数据处理之增删改
#0. 储备工作
USE atguigudb;
CREATE TABLE IF NOT EXISTS emp1(
id INT,
`name` VARCHAR(15),
hire_date DATE,
salary DOUBLE(10,2)
);
DESC emp1;
SELECT *
FROM emp1;
#1. 添加数据
#方式1:一条一条的添加数据
# ① 没有指明添加的字段
#正确的
INSERT INTO emp1
VALUES (1,'Tom','2000-12-21',3400); #注意:一定要按照声明的字段的先后顺序添加
#错误的
INSERT INTO emp1
VALUES (2,3400,'2000-12-21','Jerry');
# ② 指明要添加的字段 (推荐)
INSERT INTO emp1(id,hire_date,salary,`name`)
VALUES(2,'1999-09-09',4000,'Jerry');
# 说明:没有进行赋值的hire_date 的值为 null
INSERT INTO emp1(id,salary,`name`)
VALUES(3,4500,'shk');
# ③ 同时插入多条记录 (推荐)
INSERT INTO emp1(id,NAME,salary)
VALUES
(4,'Jim',5000),
(5,'张俊杰',5500);
#方式2:将查询结果插入到表中
SELECT * FROM emp1;
INSERT INTO emp1(id,NAME,salary,hire_date)
#查询语句
SELECT employee_id,last_name,salary,hire_date # 查询的字段一定要与添加到的表的字段一一对应
FROM employees
WHERE department_id IN (70,60);
DESC emp1;
DESC employees;
#说明:emp1表中要添加数据的字段的长度不能低于employees表中查询的字段的长度。
# 如果emp1表中要添加数据的字段的长度低于employees表中查询的字段的长度的话,就有添加不成功的风险。
#2. 更新数据 (或修改数据)
# UPDATE .... SET .... WHERE ...
# 可以实现批量修改数据的。
UPDATE emp1
SET hire_date = CURDATE()
WHERE id = 5;
SELECT * FROM emp1;
#同时修改一条数据的多个字段
UPDATE emp1
SET hire_date = CURDATE(),salary = 6000
WHERE id = 4;
#题目:将表中姓名中包含字符a的提薪20%
UPDATE emp1
SET salary = salary * 1.2
WHERE NAME LIKE '%a%';
#修改数据时,是可能存在不成功的情况的。(可能是由于约束的影响造成的)
UPDATE employees
SET department_id = 10000
WHERE employee_id = 102;
#3. 删除数据 DELETE FROM .... WHERE....
DELETE FROM emp1
WHERE id = 1;
#在删除数据时,也有可能因为约束的影响,导致删除失败
DELETE FROM departments
WHERE department_id = 50;
#小结:DML操作默认情况下,执行完以后都会自动提交数据。
# 如果希望执行完以后不自动提交数据,则需要使用 SET autocommit = FALSE.
#4. MySQL8的新特性:计算列
USE atguigudb;
CREATE TABLE test1(
a INT,
b INT,
c INT GENERATED ALWAYS AS (a + b) VIRTUAL #字段c即为计算列
);
INSERT INTO test1(a,b)
VALUES(10,20);
SELECT * FROM test1;
UPDATE test1
SET a = 100;
#5.综合案例
# 1、创建数据库test01_library
CREATE DATABASE IF NOT EXISTS test01_library CHARACTER SET 'utf8';
USE test01_library;
# 2、创建表 books,表结构如下:
CREATE TABLE IF NOT EXISTS books(
id INT,
`name` VARCHAR(50),
`authors` VARCHAR(100),
price FLOAT,
pubdate YEAR,
note VARCHAR(100),
num INT
);
DESC books;
SELECT * FROM books;
# 3、向books表中插入记录
# 1)不指定字段名称,插入第一条记录
INSERT INTO books
VALUES(1,'Tal of AAA','Dickes',23,'1995','novel',11);
# 2)指定所有字段名称,插入第二记录
INSERT INTO books(id,NAME,AUTHORS,price,pubdate,note,num)
VALUES(2,'EmmaT','Jane lura',35,'1993','joke',22);
# 3)同时插入多条记录(剩下的所有记录)
INSERT INTO books(id,NAME,AUTHORS,price,pubdate,note,num)
VALUES
(3,'Story of Jane','Jane Tim',40,2001,'novel',0),
(4,'Lovey Day','George Byron',20,2005,'novel',30),
(5,'Old land','Honore Blade',30,2010,'Law',0),
(6,'The Battle','Upton Sara',30,1999,'medicine',40),
(7,'Rose Hood','Richard haggard',28,2008,'cartoon',28);
# 4、将小说类型(novel)的书的价格都增加5。
UPDATE books
SET price = price + 5
WHERE note = 'novel';
# 5、将名称为EmmaT的书的价格改为40,并将说明改为drama。
UPDATE books
SET price = 40,note = 'drama'
WHERE NAME = 'EmmaT';
# 6、删除库存为0的记录。
DELETE FROM books
WHERE num = 0;
# 7、统计书名中包含a字母的书
SELECT NAME
FROM books
WHERE NAME LIKE '%a%';
# 8、统计书名中包含a字母的书的数量和库存总量
SELECT COUNT(*),SUM(num)
FROM books
WHERE NAME LIKE '%a%';
# 9、找出“novel”类型的书,按照价格降序排列
SELECT NAME,note,price
FROM books
WHERE note = 'novel'
ORDER BY price DESC;
# 10、查询图书信息,按照库存量降序排列,如果库存量相同的按照note升序排列
SELECT *
FROM books
ORDER BY num DESC,note ASC;
# 11、按照note分类统计书的数量
SELECT note,COUNT(*)
FROM books
GROUP BY note;
# 12、按照note分类统计书的库存量,显示库存量超过30本的
SELECT note,SUM(num)
FROM books
GROUP BY note
HAVING SUM(num) > 30;
# 13、查询所有图书,每页显示5本,显示第二页
SELECT *
FROM books
LIMIT 5,5;
# 14、按照note分类统计书的库存量,显示库存量最多的
SELECT note,SUM(num) sum_num
FROM books
GROUP BY note
ORDER BY sum_num DESC
LIMIT 0,1;
# 15、查询书名达到10个字符的书,不包括里面的空格
SELECT CHAR_LENGTH(REPLACE(NAME,' ',''))
FROM books;
SELECT NAME
FROM books
WHERE CHAR_LENGTH(REPLACE(NAME,' ','')) >= 10;
# 16、查询书名和类型,其中note值为novel显示小说,law显示法律,medicine显示医药,
#cartoon显示卡通,joke显示笑话
SELECT NAME "书名",note,CASE note WHEN 'novel' THEN '小说'
WHEN 'law' THEN '法律'
WHEN 'medicine' THEN '医药'
WHEN 'cartoon' THEN '卡通'
WHEN 'joke' THEN '笑话'
ELSE '其他'
END "类型"
FROM books;
# 17、查询书名、库存,其中num值超过30本的,显示滞销,大于0并低于10的,
#显示畅销,为0的显示需要无货
SELECT NAME AS "书名",num AS "库存", CASE WHEN num > 30 THEN '滞销'
WHEN num > 0 AND num < 10 THEN '畅销'
WHEN num = 0 THEN '无货'
ELSE '正常'
END "显示状态"
FROM books;
# 18、统计每一种note的库存量,并合计总量
SELECT IFNULL(note,'合计库存总量') AS note,SUM(num)
FROM books
GROUP BY note WITH ROLLUP;
# 19、统计每一种note的数量,并合计总量
SELECT IFNULL(note,'合计总量') AS note,COUNT(*)
FROM books
GROUP BY note WITH ROLLUP;
# 20、统计库存量前三名的图书
SELECT *
FROM books
ORDER BY num DESC
LIMIT 0,3;
# 21、找出最早出版的一本书
SELECT *
FROM books
ORDER BY pubdate ASC
LIMIT 0,1;
# 22、找出novel中价格最高的一本书
SELECT *
FROM books
WHERE note = 'novel'
ORDER BY price DESC
LIMIT 0,1;
# 23、找出书名中字数最多的一本书,不含空格
SELECT *
FROM books
ORDER BY CHAR_LENGTH(REPLACE(NAME,' ','')) DESC
LIMIT 0,1;数据处理之增删改练习
#练习1:
#1. 创建数据库dbtest11
CREATE DATABASE IF NOT EXISTS dbtest11 CHARACTER SET 'utf8';
#2. 运行以下脚本创建表my_employees
USE dbtest11;
CREATE TABLE my_employees(
id INT(10),
first_name VARCHAR(10),
last_name VARCHAR(10),
userid VARCHAR(10),
salary DOUBLE(10,2)
);
CREATE TABLE users(
id INT,
userid VARCHAR(10),
department_id INT
);
#3.显示表my_employees的结构
DESC my_employees;
DESC users;
#4.向my_employees表中插入下列数据
ID FIRST_NAME LAST_NAME USERID SALARY
1 patel Ralph Rpatel 895
2 Dancs Betty Bdancs 860
3 Biri Ben Bbiri 1100
4 Newman Chad Cnewman 750
5 Ropeburn Audrey Aropebur 1550
INSERT INTO my_employees
VALUES(1,'patel','Ralph','Rpatel',895);
INSERT INTO my_employees VALUES
(2,'Dancs','Betty','Bdancs',860),
(3,'Biri','Ben','Bbiri',1100),
(4,'Newman','Chad','Cnewman',750),
(5,'Ropeburn','Audrey','Aropebur',1550);
SELECT * FROM my_employees;
DELETE FROM my_employees;
#方式2:
INSERT INTO my_employees
SELECT 1,'patel','Ralph','Rpatel',895 UNION ALL
SELECT 2,'Dancs','Betty','Bdancs',860 UNION ALL
SELECT 3,'Biri','Ben','Bbiri',1100 UNION ALL
SELECT 4,'Newman','Chad','Cnewman',750 UNION ALL
SELECT 5,'Ropeburn','Audrey','Aropebur',1550;
#5.向users表中插入数据
1 Rpatel 10
2 Bdancs 10
3 Bbiri 20
4 Cnewman 30
5 Aropebur 40
INSERT INTO users VALUES
(1,'Rpatel',10),
(2,'Bdancs',10),
(3,'Bbiri',20),
(4,'Cnewman',30),
(5,'Aropebur',40)
SELECT * FROM users;
#6. 将3号员工的last_name修改为“drelxer”
UPDATE my_employees
SET last_name = 'drelxer'
WHERE id = 3;
#7. 将所有工资少于900的员工的工资修改为1000
UPDATE my_employees
SET salary = 1000
WHERE salary < 900;
#8. 将userid为Bbiri的users表和my_employees表的记录全部删除
#方式1:
DELETE FROM my_employees
WHERE userid = 'Bbiri';
DELETE FROM users
WHERE userid = 'Bbiri';
#方式2:
DELETE m,u
FROM my_employees m
JOIN users u
ON m.userid = u.userid
WHERE m.userid = 'Bbiri';
SELECT * FROM my_employees;
SELECT * FROM users;
#9. 删除my_employees、users表所有数据
DELETE FROM my_employees;
DELETE FROM users;
#10. 检查所作的修正
SELECT * FROM my_employees;
SELECT * FROM users;
#11. 清空表my_employees
TRUNCATE TABLE my_employees;
##########################################
#练习2:
# 1. 使用现有数据库dbtest11
USE dbtest11;
# 2. 创建表格pet
CREATE TABLE pet(
NAME VARCHAR(20),
OWNER VARCHAR(20),
species VARCHAR(20),
sex CHAR(1),
birth YEAR,
death YEAR
);
DESC pet;
# 3. 添加记录
INSERT INTO pet VALUES
('Fluffy','harold','Cat','f','2003','2010'),
('Claws','gwen','Cat','m','2004',NULL),
('Buffy',NULL,'Dog','f','2009',NULL),
('Fang','benny','Dog','m','2000',NULL),
('bowser','diane','Dog','m','2003','2009'),
('Chirpy',NULL,'Bird','f','2008',NULL);
SELECT *
FROM pet;
# 4. 添加字段:主人的生日owner_birth DATE类型。
ALTER TABLE pet
ADD owner_birth DATE;
# 5. 将名称为Claws的猫的主人改为kevin
UPDATE pet
SET OWNER = 'kevin'
WHERE NAME = 'Claws' AND species = 'Cat';
# 6. 将没有死的狗的主人改为duck
UPDATE pet
SET OWNER = 'duck'
WHERE death IS NULL AND species = 'Dog';
# 7. 查询没有主人的宠物的名字;
SELECT NAME
FROM pet
WHERE OWNER IS NULL;
# 8. 查询已经死了的cat的姓名,主人,以及去世时间;
SELECT NAME,OWNER,death
FROM pet
WHERE death IS NOT NULL;
# 9. 删除已经死亡的狗
DELETE FROM pet
WHERE death IS NOT NULL
AND species = 'Dog';
# 10. 查询所有宠物信息
SELECT *
FROM pet;
##################################
#练习3:
# 1. 使用已有的数据库dbtest11
USE dbtest11;
# 2. 创建表employee,并添加记录
CREATE TABLE employee(
id INT,
NAME VARCHAR(15),
sex CHAR(1),
tel VARCHAR(25),
addr VARCHAR(35),
salary DOUBLE(10,2)
);
INSERT INTO employee VALUES
(10001,'张一一','男','13456789000','山东青岛',1001.58),
(10002,'刘小红','女','13454319000','河北保定',1201.21),
(10003,'李四','男','0751-1234567','广东佛山',1004.11),
(10004,'刘小强','男','0755-5555555','广东深圳',1501.23),
(10005,'王艳','男','020-1232133','广东广州',1405.16);
SELECT * FROM employee;
# 3. 查询出薪资在1200~1300之间的员工信息。
SELECT *
FROM employee
WHERE salary BETWEEN 1200 AND 1300;
# 4. 查询出姓“刘”的员工的工号,姓名,家庭住址。
SELECT id,NAME,addr
FROM employee
WHERE NAME LIKE '刘%';
# 5. 将“李四”的家庭住址改为“广东韶关”
UPDATE employee
SET addr = '广东韶关'
WHERE NAME = '李四';
# 6. 查询出名字中带“小”的员工
SELECT *
FROM employee
WHERE NAME LIKE '%小%';MySQL数据类型
# 建议使用 MySQL5.7进行测试。
#1.关于属性:character set name
SHOW VARIABLES LIKE 'character_%';
#创建数据库时指名字符集
CREATE DATABASE IF NOT EXISTS dbtest12 CHARACTER SET 'utf8';
SHOW CREATE DATABASE dbtest12;
#创建表的时候,指名表的字符集
CREATE TABLE temp(
id INT
) CHARACTER SET 'utf8';
SHOW CREATE TABLE temp;
#创建表,指名表中的字段时,可以指定字段的字符集
CREATE TABLE temp1(
id INT,
NAME VARCHAR(15) CHARACTER SET 'gbk'
);
SHOW CREATE TABLE temp1;
#2.整型数据类型
USE dbtest12;
CREATE TABLE test_int1(
f1 TINYINT,
f2 SMALLINT,
f3 MEDIUMINT,
f4 INTEGER,
f5 BIGINT
);
DESC test_int1;
INSERT INTO test_int1(f1)
VALUES(12),(-12),(-128),(127);
SELECT * FROM test_int1;
#Out of range value for column 'f1' at row 1
INSERT INTO test_int1(f1)
VALUES(128);
CREATE TABLE test_int2(
f1 INT,
f2 INT(5),
f3 INT(5) ZEROFILL #① 显示宽度为5。当insert的值不足5位时,使用0填充。 ②当使用ZEROFILL时,自动会添加UNSIGNED
)
#M : 表示显示宽度,M的取值范围是(0, 255)。例如,int(5):当数据宽度小于5位的时候在数字前面需要用
#字符填满宽度。该项功能需要配合“ ZEROFILL ”使用,表示用“0”填满宽度,否则指定显示宽度无效。
#如果设置了显示宽度,那么插入的数据宽度超过显示宽度限制,会不会截断或插入失败?
#答案:不会对插入的数据有任何影响,还是按照类型的实际宽度进行保存,即 显示宽度与类型可以存储的
#值范围无关 。从MySQL 8.0.17开始,整数数据类型不推荐使用显示宽度属性。
#,int(M),必须和UNSIGNED ZEROFILL一起使用才有意义。如果整
#数值超过M位,就按照实际位数存储。只是无须再用字符 0 进行填充。
#MySQL 存储浮点数的格式为: 符号(S) 、 尾数(M) 和 阶码(E) 。因此,无论有没有符号,MySQL 的浮
#点数都会存储表示符号的部分。因此, 所谓的无符号数取值范围,其实就是有符号数取值范围大于等于零的部分。
#在8.0之后就不用可以的加入关键字 unsigned 关键字了,以为有符号无符号占有的位数总是那些。
INSERT INTO test_int2(f1,f2)
VALUES(123,123),(123456,123456);
SELECT * FROM test_int2;
INSERT INTO test_int2(f3)
VALUES(123),(123456);
SHOW CREATE TABLE test_int2;
CREATE TABLE test_int3(
f1 INT UNSIGNED
);
DESC test_int3;
INSERT INTO test_int3
VALUES(2412321);
#Out of range value for column 'f1' at row 1
INSERT INTO test_int3
VALUES(4294967296);
#3.浮点类型
#FLOAT和DOUBLE类型在不指定(M,D)时,默认会按照实际的精度(由实际的硬件和操作系统决定)来显示。
#从MySQL 8.0.17开始,FLOAT(M,D) 和DOUBLE(M,D)用法在官方文档中已经明确不推荐使用,将来可
#能被移除。另外,关于浮点型FLOAT和DOUBLE的UNSIGNED也不推荐使用了,将来也可能被移除。
CREATE TABLE test_double1(
f1 FLOAT,
f2 FLOAT(5,2),
f3 DOUBLE,
f4 DOUBLE(5,2)
);
DESC test_double1;
INSERT INTO test_double1(f1,f2)
VALUES(123.45,123.45);
SELECT * FROM test_double1;
INSERT INTO test_double1(f3,f4)
VALUES(123.45,123.456); #存在四舍五入
#Out of range value for column 'f4' at row 1
INSERT INTO test_double1(f3,f4)
VALUES(123.45,1234.456);
#Out of range value for column 'f4' at row 1
INSERT INTO test_double1(f3,f4)
VALUES(123.45,999.995);
#测试FLOAT和DOUBLE的精度问题
CREATE TABLE test_double2(
f1 DOUBLE
);
INSERT INTO test_double2
VALUES(0.47),(0.44),(0.19);
#查询结果是 1.0999999999999999。
#原因:如果小数尾数不是 0 或 5(比如 9.624),你就无法用一个二进制数来精确表达。进而,就只好在取值允许的范围内进行四舍五入。
#因为浮点数是不准确的,所以我们要避免使用“=”来判断两个数是否相等。
SELECT SUM(f1)
FROM test_double2;
SELECT SUM(f1) = 1.1,1.1 = 1.1
FROM test_double2;
#4. 定点数类型
#MySQL 有没有精准的数据类型呢?当然有,这就是定点数类型: DECIMAL 。
#DECIMAL(M,D)的最大取值范围与DOUBLE类型一样,但是有效的数据范围是由M和D决定的。
#DECIMAL 的存储空间并不是固定的,由精度值M决定,总共占用的存储空间为M+2个字节。也就是说,在一些对精度要求不高的场景下,比起占用同样字节长度的定点数,浮点数表达的数值范围可以更大一些。
#定点数在MySQL内部是以 字符串 的形式进行存储,这就决定了它一定是精准的。
#当DECIMAL类型不指定精度和标度时,其默认为DECIMAL(10,0)。当数据的精度超出了定点数类型的精度范围时,则MySQL同样会进行四舍五入处理。
#浮点数 vs 定点数
#浮点数相对于定点数的优点是在长度一定的情况下,浮点类型取值范围大,但是不精准,适用于需要取值范围大,又可以容忍微小误差的科学计算场景(比如计算化学、分子建模、流体动力学等)
#定点数类型取值范围相对小,但是精准,没有误差,适合于对精度要求极高的场景 (比如涉及金额计算的场景)
#开发经验:
#“由于 DECIMAL 数据类型的精准性,在我们的项目中,除了极少数(比如商品编号)用到整数类型外,其他的数值都用的是 DECIMAL,原因就是这个项目所处的零售行业,要求精准,一分钱也不能差。 ” ——来自某项目经理
CREATE TABLE test_decimal1(
f1 DECIMAL,
f2 DECIMAL(5,2)
);
DESC test_decimal1;
INSERT INTO test_decimal1(f1)
VALUES(123),(123.45);
SELECT * FROM test_decimal1;
INSERT INTO test_decimal1(f2)
VALUES(999.99);
INSERT INTO test_decimal1(f2)
VALUES(67.567);#存在四色五入
#Out of range value for column 'f2' at row 1
INSERT INTO test_decimal1(f2)
VALUES(1267.567);
#Out of range value for column 'f2' at row 1
INSERT INTO test_decimal1(f2)
VALUES(999.995);
#演示DECIMAL替换DOUBLE,体现精度
ALTER TABLE test_double2
MODIFY f1 DECIMAL(5,2);
DESC test_double2;
SELECT SUM(f1)
FROM test_double2;
SELECT SUM(f1) = 1.1,1.1 = 1.1
FROM test_double2;
#5. 位类型:BIT
#BIT类型,如果没有指定(M),默认是1位。这个1位,表示只能存1位的二进制值。这里(M)是表示二进制的位数,位数最小值为1,最大值为64。
CREATE TABLE test_bit1(
f1 BIT,
f2 BIT(5),
f3 BIT(64)
);
DESC test_bit1;
INSERT INTO test_bit1(f1)
VALUES(0),(1);
SELECT *
FROM test_bit1;
#Data too long for column 'f1' at row 1
INSERT INTO test_bit1(f1)
VALUES(2);
INSERT INTO test_bit1(f2)
VALUES(31);
#Data too long for column 'f2' at row 1
INSERT INTO test_bit1(f2)
VALUES(32);
#BIN查看2二进制数据,HEX查看16进制数据
SELECT BIN(f1),BIN(f2),HEX(f1),HEX(f2)
FROM test_bit1;
#此时+0以后,可以以十进制的方式显示数据
SELECT f1 + 0, f2 + 0
FROM test_bit1;
#6.1 YEAR类型
#从MySQL5.5.27开始,2位格式的YEAR已经不推荐使用。YEAR默认格式就是“YYYY”,没必要写成YEAR(4),
#从MySQL 8.0.19开始,不推荐使用指定显示宽度的YEAR(4)数据类型。
#DATE类型表示日期,没有时间部分,格式为 YYYY-MM-DD ,其中,YYYY表示年份,MM表示月份,DD表示日期。需要 3个字节 的存储空间。
#使用 CURRENT_DATE() 或者 NOW() 函数,会插入当前系统的日期。
CREATE TABLE test_year(
f1 YEAR,
f2 YEAR(4)
);
DESC test_year;
INSERT INTO test_year(f1)
VALUES('2021'),(2022);
SELECT * FROM test_year;
INSERT INTO test_year(f1)
VALUES ('2155');
#Out of range value for column 'f1' at row 1
INSERT INTO test_year(f1)
VALUES ('2156');
INSERT INTO test_year(f1)
VALUES ('69'),('70');
INSERT INTO test_year(f1)
VALUES (0),('00');
#6.2 DATE类型
CREATE TABLE test_date1(
f1 DATE
);
DESC test_date1;
INSERT INTO test_date1
VALUES ('2020-10-01'), ('20201001'),(20201001);
INSERT INTO test_date1
VALUES ('00-01-01'), ('000101'), ('69-10-01'), ('691001'), ('70-01-01'), ('700101'), ('99-01-01'), ('990101');
INSERT INTO test_date1
VALUES (000301), (690301), (700301), (990301); #存在隐式转换
INSERT INTO test_date1
VALUES (CURDATE()),(CURRENT_DATE()),(NOW());
SELECT *
FROM test_date1;
#6.3 TIME类型
#可以使用带有冒号的字符串,比如' D HH:MM:SS' 、' HH:MM:SS '、'HH:MM '、' D HH:MM '、' D HH '或' SS '格式,都能被正确地插入TIME类型的字段中。其中D表示天,其最小值为0,最大值为34。如果使用带有D格式的字符串插入TIME类型的字段时,D会被转化为小时,计算格式为D*24+HH。当使用带有冒号并且不带D的字符串表示时间时,表示当天的时间,比如12:10表示12:10:00,而不是00:12:10。
#使用 CURRENT_TIME() 或者 NOW() ,会插入当前系统的时间。
#(2)可以使用不带有冒号的字符串或者数字,格式为' HHMMSS '或者HHMMSS 。如果插入一个不合法的字符串或者数字,MySQL在存储数据时,会将其自动转化为00:00:00进行存储。比如1210,MySQL会将最右边的两位解析成秒,表示00:12:10,而不是12:10:00。
CREATE TABLE test_time1(
f1 TIME
);
DESC test_time1;
INSERT INTO test_time1
VALUES('2 12:30:29'), ('12:35:29'), ('12:40'), ('2 12:40'),('1 05'), ('45');
INSERT INTO test_time1
VALUES ('123520'), (124011),(1210);
INSERT INTO test_time1
VALUES (NOW()), (CURRENT_TIME()),(CURTIME());
SELECT *
FROM test_time1;
#6.4 DATETIME类型
#DATETIME类型在所有的日期时间类型中占用的存储空间最大,总共需要 8 个字节的存储空间。
#使用函数 CURRENT_TIMESTAMP() 和 NOW() ,可以向DATETIME类型的字段插入系统的当前日期和时间。
CREATE TABLE test_datetime1(
dt DATETIME
);
INSERT INTO test_datetime1
VALUES ('2021-01-01 06:50:30'), ('20210101065030');
INSERT INTO test_datetime1
VALUES ('99-01-01 00:00:00'), ('990101000000'), ('20-01-01 00:00:00'), ('200101000000');
INSERT INTO test_datetime1
VALUES (20200101000000), (200101000000), (19990101000000), (990101000000);
INSERT INTO test_datetime1
VALUES (CURRENT_TIMESTAMP()), (NOW()),(SYSDATE());
SELECT *
FROM test_datetime1;
#6.5 TIMESTAMP类型
#存储数据的时候需要对当前时间所在的时区进行转换,查询数据的时候再将时间转换回当前的时区。因此,使用TIMESTAMP存储的同一个时间值,在不同的时区查询时会显示不同的时间。
#TIMESTAMP类型也可以表示日期时间,其显示格式与DATETIME类型相同,都是 YYYY-MM-DDHH:MM:SS ,需要4个字节的存储空间。但是TIMESTAMP存储的时间范围比DATETIME要小很多,只能存储“1970-01-01 00:00:01 UTC”到“2038-01-19 03:14:07 UTC”之间的时间。
CREATE TABLE test_timestamp1(
ts TIMESTAMP
);
INSERT INTO test_timestamp1
VALUES ('1999-01-01 03:04:50'), ('19990101030405'), ('99-01-01 03:04:05'), ('990101030405');
INSERT INTO test_timestamp1
VALUES ('2020@01@01@00@00@00'), ('20@01@01@00@00@00');
INSERT INTO test_timestamp1
VALUES (CURRENT_TIMESTAMP()), (NOW());
#Incorrect datetime value
INSERT INTO test_timestamp1
VALUES ('2038-01-20 03:14:07');
SELECT *
FROM test_timestamp1;
#对比DATETIME 和 TIMESTAMP
#TIMESTAMP和DATETIME的区别:
# TIMESTAMP存储空间比较小,表示的日期时间范围也比较小
# 底层存储方式不同,TIMESTAMP底层存储的是毫秒值,距离1970-1-1 0:0:0 0毫秒的毫秒值。
# 两个日期比较大小或日期计算时,TIMESTAMP更方便、更快。
# TIMESTAMP和时区有关。TIMESTAMP会根据用户的时区不同,显示不同的结果。而DATETIME则只能反映出插入时当地的时区,其他时区的人查看数据必然会有误差的。
CREATE TABLE temp_time(
d1 DATETIME,
d2 TIMESTAMP
);
INSERT INTO temp_time VALUES('2021-9-2 14:45:52','2021-9-2 14:45:52');
INSERT INTO temp_time VALUES(NOW(),NOW());
SELECT * FROM temp_time;
#修改当前的时区
SET time_zone = '+9:00';
SELECT * FROM temp_time;
#在开发中用得最多的日期时间类型,就是 DATETIME
#一般存注册时间、商品发布时间等,不建议使用DATETIME存储,而是使用 时间戳 ,因为DATETIME虽然直观,但不便于计算。
#VARCHAR(M) 占用的存储空间 (实际长度 + 1) 个字节
#CHAR(M) 固定长度 M个字节
#7.1 CHAR类型
#CHAR类型:
# CHAR(M) 类型一般需要预先定义字符串长度。如果不指定(M),则表示长度默认是1个字符。
# 如果保存时,数据的实际长度比CHAR类型声明的长度小,则会在 右侧填充 空格以达到指定的长度。当MySQL检索CHAR类型的数据时,CHAR类型的字段会去除尾部的空格。
# 定义CHAR类型字段时,声明的字段长度即为CHAR类型字段所占的存储空间的字节数。
CREATE TABLE test_char1(
c1 CHAR,
c2 CHAR(5)
);
DESC test_char1;
INSERT INTO test_char1(c1)
VALUES('a');
#Data too long for column 'c1' at row 1
INSERT INTO test_char1(c1)
VALUES('ab');
INSERT INTO test_char1(c2)
VALUES('ab');
INSERT INTO test_char1(c2)
VALUES('hello');
INSERT INTO test_char1(c2)
VALUES('尚');
INSERT INTO test_char1(c2)
VALUES('硅谷');
INSERT INTO test_char1(c2)
VALUES('尚硅谷教育');
#Data too long for column 'c2' at row 1
INSERT INTO test_char1(c2)
VALUES('尚硅谷IT教育');
SELECT * FROM test_char1;
SELECT CONCAT(c2,'***')
FROM test_char1;
INSERT INTO test_char1(c2)
VALUES('ab ');
SELECT CHAR_LENGTH(c2)
FROM test_char1;
#7.2 VARCHAR类型
CREATE TABLE test_varchar1(
NAME VARCHAR #错误
);
#Column length too big for column 'name' (max = 21845); use BLOB or TEXT instead
CREATE TABLE test_varchar2(
NAME VARCHAR(65535)
);
CREATE TABLE test_varchar3(
NAME VARCHAR(5)
);
INSERT INTO test_varchar3
VALUES('尚硅谷'),('尚硅谷教育');
#Data too long for column 'NAME' at row 1
INSERT INTO test_varchar3
VALUES('尚硅谷IT教育');
哪些情况使用 CHAR 或 VARCHAR 更好:

情况1:存储很短的信息。比如门牌号码101,201……这样很短的信息应该用char,因为varchar还要占个 byte用于存储信息长度,本来打算节约存储的,结果得不偿失。
情况3:十分频繁改变的column。因为varchar每次存储都要有额外的计算,得到长度等工作,如果一个 非常频繁改变的,那就要有很多的精力用于计算,而这些对于char来说是不需要的。
情况4:具体存储引擎中的情况:
MyISAM 数据存储引擎和数据列:MyISAM数据表,最好使用固定长度(CHAR)的数据列代替可变长 度(VARCHAR)的数据列。这样使得整个表静态化,从而使 数据检索更快 ,用空间换时间。
MEMORY 存储引擎和数据列:MEMORY数据表目前都使用固定长度的数据行存储,因此无论使用 CHAR或VARCHAR列都没有关系,两者都是作为CHAR类型处理的。
InnoDB 存储引擎,建议使用VARCHAR类型。因为对于InnoDB数据表,内部的行存储格式并没有区 分固定长度和可变长度列(所有数据行都使用指向数据列值的头指针),而且主要影响性能的因素 是数据行使用的存储总量,由于char平均占用的空间多于varchar,所以除了简短并且固定长度的, 其他考虑varchar。这样节省空间,对磁盘I/O和数据存储总量比较好。
7.3 TEXT类型
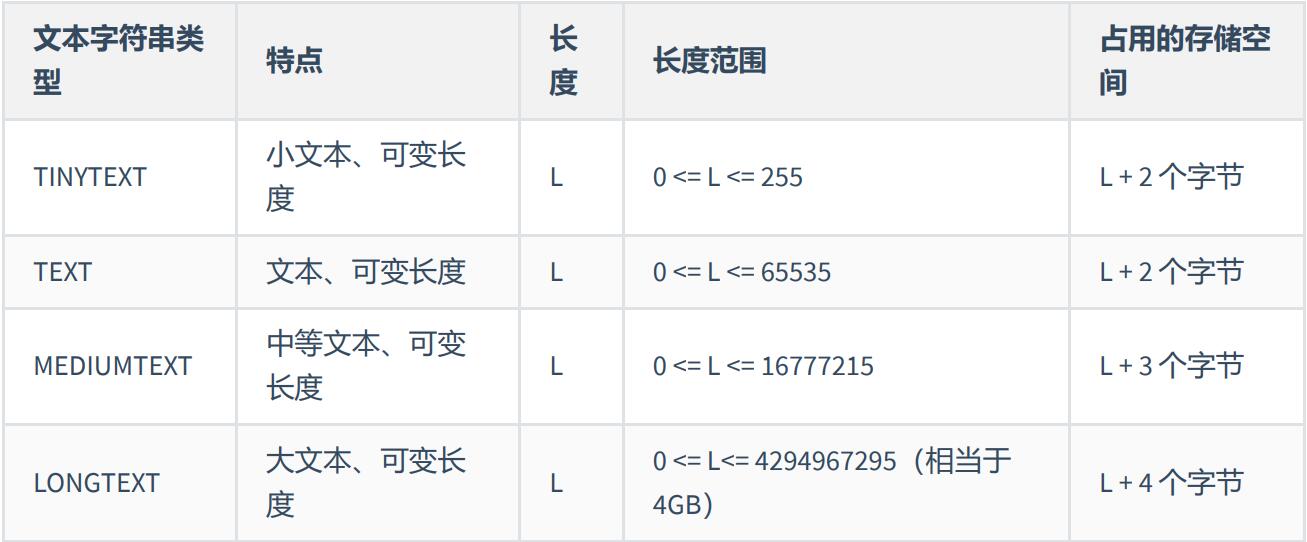
#7.3 TEXT类型
CREATE TABLE test_text(
tx TEXT
);
INSERT INTO test_text
VALUES('atguigu ');
SELECT CHAR_LENGTH(tx)
FROM test_text; #10
开发中经验: TEXT文本类型,可以存比较大的文本段,搜索速度稍慢,因此如果不是特别大的内容,建议使用CHAR, VARCHAR来代替。还有TEXT类型不用加默认值,加了也没用。而且text和blob类型的数据删除后容易导致 “空洞”,使得文件碎片比较多,所以频繁使用的表不建议包含TEXT类型字段,建议单独分出去,单独用 一个表。
8.ENUM类型
#8. ENUM类型
CREATE TABLE test_enum(
season ENUM('春','夏','秋','冬','unknow')
);
INSERT INTO test_enum
VALUES('春'),('秋');
SELECT * FROM test_enum;
#Data truncated for column 'season' at row 1
INSERT INTO test_enum
VALUES('春,秋');
#Data truncated for column 'season' at row 1
INSERT INTO test_enum
VALUES('人');
INSERT INTO test_enum
VALUES('unknow');
#忽略大小写的
INSERT INTO test_enum
VALUES('UNKNOW');
#可以使用索引进行枚举元素的调用
INSERT INTO test_enum
VALUES(1),('3');
# 没有限制非空的情况下,可以添加null值
INSERT INTO test_enum
VALUES (NULL);
#9. SET类型
CREATE TABLE test_set(
s SET ('A', 'B', 'C')
);
INSERT INTO test_set (s) VALUES ('A'), ('A,B');
#插入重复的SET类型成员时,MySQL会自动删除重复的成员
INSERT INTO test_set (s) VALUES ('A,B,C,A');
#向SET类型的字段插入SET成员中不存在的值时,MySQL会抛出错误。
INSERT INTO test_set (s) VALUES ('A,B,C,D');
SELECT *
FROM test_set;
CREATE TABLE temp_mul(
gender ENUM('男','女'),
hobby SET('吃饭','睡觉','打豆豆','写代码')
);
INSERT INTO temp_mul
VALUES('男','睡觉,打豆豆');
SELECT *
FROM temp_mul;
#Data truncated for column 'gender' at row 1
INSERT INTO temp_mul
VALUES('男,女','睡觉,打豆豆');
10.BINARY 与 VARBINARY类型,Blob类型
BINARY与VARBINARY类型
BINARY和VARBINARY类似于CHAR和VARCHAR,只是它们存储的是二进制字符串。
BINARY (M)为固定长度的二进制字符串,M表示最多能存储的字节数,取值范围是0~255个字符。如果未 指定(M),表示只能存储 1个字节 。例如BINARY (8),表示最多能存储8个字节,如果字段值不足(M)个字 节,将在右边填充’\0’以补齐指定长度。
VARBINARY (M)为可变长度的二进制字符串,M表示最多能存储的字节数,总字节数不能超过行的字节长 度限制65535,另外还要考虑额外字节开销,VARBINARY类型的数据除了存储数据本身外,还需要1或2个 字节来存储数据的字节数。VARBINARY类型 必须指定(M) ,否则报错。

BLOB是一个 二进制大对象 ,可以容纳可变数量的数据。
MySQL中的BLOB类型包括TINYBLOB、BLOB、MEDIUMBLOB和LONGBLOB 4种类型,它们可容纳值的最大 长度不同。可以存储一个二进制的大对象,比如 图片 、 音频 和 视频 等。
需要注意的是,在实际工作中,往往不会在MySQL数据库中使用BLOB类型存储大对象数据,通常会将图 片、音频和视频文件存储到 服务器的磁盘上 ,并将图片、音频和视频的访问路径存储到MySQL中。
#10.1 BINARY 与 VARBINARY类型
CREATE TABLE test_binary1(
f1 BINARY,
f2 BINARY(3),
#f3 VARBINARY,
f4 VARBINARY(10)
);
DESC test_binary1;
INSERT INTO test_binary1(f1,f2)
VALUES('a','abc');
SELECT * FROM test_binary1;
#Data too long for column 'f1' at row 1
INSERT INTO test_binary1(f1)
VALUES('ab');
INSERT INTO test_binary1(f2,f4)
VALUES('ab','ab');
SELECT LENGTH(f2),LENGTH(f4)
FROM test_binary1;
#10.2 Blob类型
CREATE TABLE test_blob1(
id INT,
img MEDIUMBLOB
);
INSERT INTO test_blob1(id)
VALUES (1001);
SELECT *
FROM test_blob1;
11.JSON类型
#11. JSON类型
CREATE TABLE test_json(
js json
);
INSERT INTO test_json (js)
VALUES ('{"name":"songhk", "age":18, "address":{"province":"beijing", "city":"beijing"}}');
SELECT * FROM test_json;
SELECT js -> '$.name' AS NAME,js -> '$.age' AS age ,js -> '$.address.province' AS province, js -> '$.address.city' AS city
FROM test_json;阿里巴巴《Java开发手册》之MySQL数据库:
任何字段如果为非负数,必须是 UNSIGNED
【 强制 】小数类型为 DECIMAL,禁止使用 FLOAT 和 DOUBLE。
说明:在存储的时候,FLOAT 和 DOUBLE 都存在精度损失的问题,很可能在比较值的时候,得 到不正确的结果。如果存储的数据范围超过 DECIMAL 的范围,建议将数据拆成整数和小数并 分开存储。
【 强制 】如果存储的字符串长度几乎相等,使用 CHAR 定长字符串类型。
【 强制 】VARCHAR 是可变长字符串,不预先分配存储空间,长度不要超过 5000。如果存储长度大 于此值,定义字段类型为 TEXT,独立出来一张表,用主键来对应,避免影响其它字段索引效率。
约束
为什么需要约束
数据完整性(Data Integrity)是指数据的精确性(Accuracy)和可靠性(Reliability)。它是防止数据库中 存在不符合语义规定的数据和防止因错误信息的输入输出造成无效操作或错误信息而提出的。
为了保证数据的完整性,SQL规范以约束的方式对表数据进行额外的条件限制。从以下四个方面考虑:
实体完整性(Entity Integrity) :例如,同一个表中,不能存在两条完全相同无法区分的记录
域完整性(Domain Integrity) :例如:年龄范围0-120,性别范围“男/女”
引用完整性(Referential Integrity) :例如:员工所在部门,在部门表中要能找到这个部门
用户自定义完整性(User-defined Integrity) :例如:用户名唯一、密码不能为空等,本部门经理的工资不得高于本部门职工的平均工资的5倍。
#第13章_约束
/*
1. 基础知识
1.1 为什么需要约束? 为了保证数据的完整性!
1.2 什么叫约束?对表中字段的限制。
1.3 约束的分类:
角度1:约束的字段的个数
单列约束 vs 多列约束
角度2:约束的作用范围
列级约束:将此约束声明在对应字段的后面
表级约束:在表中所有字段都声明完,在所有字段的后面声明的约束
角度3:约束的作用(或功能)
① not null (非空约束)
② unique (唯一性约束)
③ primary key (主键约束)
④ foreign key (外键约束)
⑤ check (检查约束)
⑥ default (默认值约束)
1.4 如何添加/删除约束?
CREATE TABLE时添加约束
ALTER TABLE 时增加约束、删除约束
*/
#2. 如何查看表中的约束
SELECT * FROM information_schema.table_constraints
WHERE table_name = 'test1';
CREATE DATABASE dbtest13;
USE dbtest13;
#3. not null (非空约束)
#3.1 在CREATE TABLE时添加约束
CREATE TABLE test1(
id INT NOT NULL,
last_name VARCHAR(15) NOT NULL,
email VARCHAR(25),
salary DECIMAL(10,2)
);
DESC test1;
INSERT INTO test1(id,last_name,email,salary)
VALUES(1,'Tom','tom@126.com',3400);
#错误:Column 'last_name' cannot be null
INSERT INTO test1(id,last_name,email,salary)
VALUES(2,NULL,'tom1@126.com',3400);
#错误:Column 'id' cannot be null
INSERT INTO test1(id,last_name,email,salary)
VALUES(NULL,'Jerry','jerry@126.com',3400);
INSERT INTO test1(id,email)
VALUES(2,'abc@126.com');
UPDATE test1
SET last_name = NULL
WHERE id = 1;
UPDATE test1
SET email = 'tom@126.com'
WHERE id = 1;
#3.2 在ALTER TABLE时添加约束
SELECT * FROM test1;
DESC test1;
#如果存在null不能添加 not null约束
ALTER TABLE test1
MODIFY email VARCHAR(25) NOT NULL;
#3.3 在ALTER TABLE时删除约束
ALTER TABLE test1
MODIFY email VARCHAR(25) NULL;
#4. unique (唯一性约束)
#4.1 在CREATE TABLE时添加约束
CREATE TABLE test2(
id INT UNIQUE, #列级约束
last_name VARCHAR(15) ,
email VARCHAR(25),
salary DECIMAL(10,2),
#表级约束(会为约束起一个名字uk_test2_email)
CONSTRAINT uk_test2_email UNIQUE(email)
);
DESC test2;
SELECT * FROM information_schema.table_constraints
WHERE table_name = 'test2';
#在创建唯一约束的时候,如果不给唯一约束命名,就默认和列名相同。
INSERT INTO test2(id,last_name,email,salary)
VALUES(1,'Tom','tom@126.com',4500);
#错误:Duplicate entry '1' for key 'test2.id'
INSERT INTO test2(id,last_name,email,salary)
VALUES(1,'Tom1','tom1@126.com',4600);
#错误:Duplicate entry 'tom@126.com' for key 'test2.uk_test2_email'
INSERT INTO test2(id,last_name,email,salary)
VALUES(2,'Tom1','tom@126.com',4600);
#可以向声明为unique的字段上添加null值。而且可以多次添加null
INSERT INTO test2(id,last_name,email,salary)
VALUES(2,'Tom1',NULL,4600);
INSERT INTO test2(id,last_name,email,salary)
VALUES(3,'Tom2',NULL,4600);
SELECT * FROM test2;
#4.2 在ALTER TABLE时添加约束
DESC test2;
UPDATE test2
SET salary = 5000
WHERE id = 3;
#方式1:
ALTER TABLE test2
ADD CONSTRAINT uk_test2_sal UNIQUE(salary);
#方式2:
ALTER TABLE test2
MODIFY last_name VARCHAR(15) UNIQUE;
#4.3 复合的唯一性约束
CREATE TABLE USER(
id INT,
`name` VARCHAR(15),
`password` VARCHAR(25),
#表级约束
CONSTRAINT uk_user_name_pwd UNIQUE(`name`,`password`)
);
INSERT INTO USER
VALUES(1,'Tom','abc');
#可以成功的:
INSERT INTO USER
VALUES(1,'Tom1','abc');
SELECT *
FROM USER;
#案例:复合的唯一性约束的案例
#学生表
CREATE TABLE student(
sid INT, #学号
sname VARCHAR(20), #姓名
tel CHAR(11) UNIQUE KEY, #电话
cardid CHAR(18) UNIQUE KEY #身份证号
);
#课程表
CREATE TABLE course(
cid INT, #课程编号
cname VARCHAR(20) #课程名称
);
#选课表
CREATE TABLE student_course(
id INT,
sid INT, #学号
cid INT, #课程编号
score INT,
UNIQUE KEY(sid,cid) #复合唯一
);
INSERT INTO student VALUES(1,'张三','13710011002','101223199012015623');#成功
INSERT INTO student VALUES(2,'李四','13710011003','101223199012015624');#成功
INSERT INTO course VALUES(1001,'Java'),(1002,'MySQL');#成功
SELECT * FROM student;
SELECT * FROM course;
INSERT INTO student_course VALUES
(1, 1, 1001, 89),
(2, 1, 1002, 90),
(3, 2, 1001, 88),
(4, 2, 1002, 56);#成功
SELECT * FROM student_course;
#错误:Duplicate entry '2-1002' for key 'student_course.sid'
INSERT INTO student_course VALUES
(5,2,1002,67);
#4.4 删除唯一性约束
-- 添加唯一性约束的列上也会自动创建唯一索引。
-- 删除唯一约束只能通过删除唯一索引的方式删除。
-- 删除时需要指定唯一索引名,唯一索引名就和唯一约束名一样。
-- 如果创建唯一约束时未指定名称,如果是单列,就默认和列名相同;如果是组合列,那么默认和()中排在第一个的列名相同。也可以自定义唯一性约束名。
SELECT * FROM information_schema.table_constraints
WHERE table_name = 'student_course';
SELECT * FROM information_schema.table_constraints
WHERE table_name = 'test2';
DESC test2;
#如何删除唯一性索引
ALTER TABLE test2
DROP INDEX last_name;
ALTER TABLE test2
DROP INDEX uk_test2_sal;
#5. primary key (主键约束)
#5.1 在CREATE TABLE时添加约束
#一个表中最多只能有一个主键约束。
#错误:Multiple primary key defined
CREATE TABLE test3(
id INT PRIMARY KEY, #列级约束
last_name VARCHAR(15) PRIMARY KEY,
salary DECIMAL(10,2),
email VARCHAR(25)
);
# 主键约束特征:非空且唯一,用于唯一的标识表中的一条记录。
CREATE TABLE test4(
id INT PRIMARY KEY, #列级约束
last_name VARCHAR(15),
salary DECIMAL(10,2),
email VARCHAR(25)
);
#MySQL的主键名总是PRIMARY,就算自己命名了主键约束名也没用。
CREATE TABLE test5(
id INT ,
last_name VARCHAR(15),
salary DECIMAL(10,2),
email VARCHAR(25),
#表级约束
CONSTRAINT pk_test5_id PRIMARY KEY(id) #没有必要起名字。
);
SELECT * FROM information_schema.table_constraints
WHERE table_name = 'test5';
INSERT INTO test4(id,last_name,salary,email)
VALUES(1,'Tom',4500,'tom@126.com');
#错误:Duplicate entry '1' for key 'test4.PRIMARY'
INSERT INTO test4(id,last_name,salary,email)
VALUES(1,'Tom',4500,'tom@126.com');
#错误:Column 'id' cannot be null
INSERT INTO test4(id,last_name,salary,email)
VALUES(NULL,'Tom',4500,'tom@126.com');
SELECT * FROM test4;
CREATE TABLE user1(
id INT,
NAME VARCHAR(15),
PASSWORD VARCHAR(25),
PRIMARY KEY (NAME,PASSWORD)
);
#如果是多列组合的复合主键约束,那么这些列都不允许为空值,并且组合的值不允许重复。
INSERT INTO user1
VALUES(1,'Tom','abc');
INSERT INTO user1
VALUES(1,'Tom1','abc');
#错误:Column 'name' cannot be null
INSERT INTO user1
VALUES(1,NULL,'abc');
SELECT * FROM user1;
#5.2 在ALTER TABLE时添加约束
CREATE TABLE test6(
id INT ,
last_name VARCHAR(15),
salary DECIMAL(10,2),
email VARCHAR(25)
);
DESC test6;
ALTER TABLE test6
ADD PRIMARY KEY (id);
#5.3 如何删除主键约束 (在实际开发中,不会去删除表中的主键约束!)
ALTER TABLE test6
DROP PRIMARY KEY;
#6. 自增长列:AUTO_INCREMENT
#5.3 特点和要求
#(1)一个表最多只能有一个自增长列
#(2)当需要产生唯一标识符或顺序值时,可设置自增长
#(3)自增长列约束的列必须是键列(主键列,唯一键列)
#(4)自增约束的列的数据类型必须是整数类型
#(5)如果自增列指定了 0 和 null,会在当前最大值的基础上自增;如果自增列手动指定了具体值,直接赋值为具体值。
# 6.1 在CREATE TABLE时添加
CREATE TABLE test7(
id INT PRIMARY KEY AUTO_INCREMENT,
last_name VARCHAR(15)
);
#开发中,一旦主键作用的字段上声明有AUTO_INCREMENT,则我们在添加数据时,就不要给主键
#对应的字段去赋值了。
INSERT INTO test7(last_name)
VALUES('Tom');
SELECT * FROM test7;
#当我们向主键(含AUTO_INCREMENT)的字段上添加0 或 null时,实际上会自动的往上添加指定的字段的数值
INSERT INTO test7(id,last_name)
VALUES(0,'Tom');
INSERT INTO test7(id,last_name)
VALUES(NULL,'Tom');
INSERT INTO test7(id,last_name)
VALUES(10,'Tom');
INSERT INTO test7(id,last_name)
VALUES(-10,'Tom');
#6.2 在ALTER TABLE 时添加
CREATE TABLE test8(
id INT PRIMARY KEY ,
last_name VARCHAR(15)
);
DESC test8;
ALTER TABLE test8
MODIFY id INT AUTO_INCREMENT;
#6.3 在ALTER TABLE 时删除
ALTER TABLE test8
MODIFY id INT ;
#6.4 MySQL 8.0新特性—自增变量的持久化
#在5.7中自增长变量在内存中维护,不重启mysql服务就一直累加,1,2,3,4
#将3,4,删掉在添加是5,如果重启mysql服务,在添加是3
#MySQL 8.0将自增主键的计数器持久化到 重做日志 中。每次计数器发生改变,都会将其写入重做日志中。如果数据库重启,InnoDB会根据重做日志中的信息来初始化计数器的内存值。
#在MySQL 5.7中演示
CREATE TABLE test9(
id INT PRIMARY KEY AUTO_INCREMENT
);
INSERT INTO test9
VALUES(0),(0),(0),(0);
SELECT * FROM test9;
DELETE FROM test9
WHERE id = 4;
INSERT INTO test9
VALUES(0);
DELETE FROM test9
WHERE id = 5;
#重启服务器
SELECT * FROM test9;
INSERT INTO test9
VALUES(0);
#在MySQL 8.0中演示
CREATE TABLE test9(
id INT PRIMARY KEY AUTO_INCREMENT
);
INSERT INTO test9
VALUES(0),(0),(0),(0);
SELECT * FROM test9;
DELETE FROM test9
WHERE id = 4;
INSERT INTO test9
VALUES(0);
DELETE FROM test9
WHERE id = 5;
#重启服务器
SELECT * FROM test9;
INSERT INTO test9
VALUES(0);
#7.foreign key (外键约束)
#7.1 在CREATE TABLE 时添加
#主表和从表;父表和子表
#①先创建主表
CREATE TABLE dept1(
dept_id INT,
dept_name VARCHAR(15)
);
#②再创建从表
CREATE TABLE emp1(
emp_id INT PRIMARY KEY AUTO_INCREMENT,
emp_name VARCHAR(15),
department_id INT,
#表级约束
CONSTRAINT fk_emp1_dept_id FOREIGN KEY (department_id) REFERENCES dept1(dept_id)
);
#上述操作报错,因为主表中的dept_id上没有主键约束或唯一性约束。
#③ 添加
ALTER TABLE dept1
ADD PRIMARY KEY (dept_id);
DESC dept1;
#④ 再创建从表
CREATE TABLE emp1(
emp_id INT PRIMARY KEY AUTO_INCREMENT,
emp_name VARCHAR(15),
department_id INT,
#表级约束
CONSTRAINT fk_emp1_dept_id FOREIGN KEY (department_id) REFERENCES dept1(dept_id)
);
DESC emp1;
SELECT * FROM information_schema.table_constraints
WHERE table_name = 'emp1';
#7.2 演示外键的效果
#添加失败
INSERT INTO emp1
VALUES(1001,'Tom',10);
#
INSERT INTO dept1
VALUES(10,'IT');
#在主表dept1中添加了10号部门以后,我们就可以在从表中添加10号部门的员工
INSERT INTO emp1
VALUES(1001,'Tom',10);
#删除失败
DELETE FROM dept1
WHERE dept_id = 10;
#更新失败
UPDATE dept1
SET dept_id = 20
WHERE dept_id = 10;
#7.3 在ALTER TABLE时添加外键约束
CREATE TABLE dept2(
dept_id INT PRIMARY KEY,
dept_name VARCHAR(15)
);
CREATE TABLE emp2(
emp_id INT PRIMARY KEY AUTO_INCREMENT,
emp_name VARCHAR(15),
department_id INT
);
ALTER TABLE emp2
ADD CONSTRAINT fk_emp2_dept_id FOREIGN KEY(department_id) REFERENCES dept2(dept_id);
SELECT * FROM information_schema.table_constraints
WHERE table_name = 'emp2';
#7.4 ### 约束等级
-- `Cascade方式`:在父表上update/delete记录时,同步update/delete掉子表的匹配记录
-- `Set null方式`:在父表上update/delete记录时,将子表上匹配记录的列设为null,但是要注意子表的外键列不能为not null
-- `No action方式`:如果子表中有匹配的记录,则不允许对父表对应候选键进行update/delete操作
-- `Restrict方式`:同no action, 都是立即检查外键约束
-- `Set default方式`(在可视化工具SQLyog中可能显示空白):父表有变更时,子表将外键列设置成一个默认的值,但Innodb不能识别
#演示:
# on update cascade on delete set null
CREATE TABLE dept(
did INT PRIMARY KEY, #部门编号
dname VARCHAR(50) #部门名称
);
CREATE TABLE emp(
eid INT PRIMARY KEY, #员工编号
ename VARCHAR(5), #员工姓名
deptid INT, #员工所在的部门
FOREIGN KEY (deptid) REFERENCES dept(did) ON UPDATE CASCADE ON DELETE SET NULL
#把修改操作设置为级联修改等级,把删除操作设置为set null等级
);
INSERT INTO dept VALUES(1001,'教学部');
INSERT INTO dept VALUES(1002, '财务部');
INSERT INTO dept VALUES(1003, '咨询部');
INSERT INTO emp VALUES(1,'张三',1001); #在添加这条记录时,要求部门表有1001部门
INSERT INTO emp VALUES(2,'李四',1001);
INSERT INTO emp VALUES(3,'王五',1002);
UPDATE dept
SET did = 1004
WHERE did = 1002;
DELETE FROM dept
WHERE did = 1004;
SELECT * FROM dept;
SELECT * FROM emp;
#结论:对于外键约束,最好是采用: `ON UPDATE CASCADE ON DELETE RESTRICT` 的方式。
#7.5 删除外键约束
#一个表中可以声明有多个外键约束
USE atguigudb;
SELECT * FROM information_schema.table_constraints
WHERE table_name = 'employees';
USE dbtest13;
SELECT * FROM information_schema.table_constraints
WHERE table_name = 'emp1';
#删除外键约束
ALTER TABLE emp1
DROP FOREIGN KEY fk_emp1_dept_id;
#再手动的删除外键约束对应的普通索引
SHOW INDEX FROM emp1;
ALTER TABLE emp1
DROP INDEX fk_emp1_dept_id;
#6.10 阿里开发规范
#【 强制 】不得使用外键与级联,一切外键概念必须在应用层解决。
#说明:(概念解释)学生表中的 student_id 是主键,那么成绩表中的 student_id 则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新,即为级联更新。外键与级联更新适用于 单机低并发 ,不适合 分布式 、 高并发集群 ;级联更新是强阻塞,存在数据库 更新风暴 的风险;外键影响数据库的 插入速度 。
#MySQL5.7 可以使用check约束,但check约束对数据验证没有任何作用。添加数据时,没有任何错误或警告
#但是MySQL 8.0中可以使用check约束了。
#8. check 约束
# MySQL5.7 不支持CHECK约束,MySQL8.0支持CHECK约束。
CREATE TABLE test10(
id INT,
last_name VARCHAR(15),
salary DECIMAL(10,2) CHECK(salary > 2000)
);
INSERT INTO test10
VALUES(1,'Tom',2500);
#添加失败
INSERT INTO test10
VALUES(2,'Tom1',1500);
SELECT * FROM test10;
#9.DEFAULT约束
#9.1 在CREATE TABLE添加约束
CREATE TABLE test11(
id INT,
last_name VARCHAR(15),
salary DECIMAL(10,2) DEFAULT 2000
);
DESC test11;
INSERT INTO test11(id,last_name,salary)
VALUES(1,'Tom',3000);
INSERT INTO test11(id,last_name)
VALUES(2,'Tom1');
SELECT *
FROM test11;
#9.2 在ALTER TABLE添加约束
CREATE TABLE test12(
id INT,
last_name VARCHAR(15),
salary DECIMAL(10,2)
);
DESC test12;
ALTER TABLE test12
MODIFY salary DECIMAL(8,2) DEFAULT 2500;
#9.3 在ALTER TABLE删除约束
ALTER TABLE test12
MODIFY salary DECIMAL(8,2);
SHOW CREATE TABLE test12;面试1、为什么建表时,加 not null default ‘’ 或 default 0
答:不想让表中出现null值。
面试2、为什么不想要 null 的值
答:
(1)不好比较。null是一种特殊值,比较时只能用专门的is null 和 is not null来比较。碰到运算符,通 常返回null。
(2)效率不高。影响提高索引效果。因此,我们往往在建表时 not null default ‘’ 或 default 0
面试3、带AUTO_INCREMENT约束的字段值是从1开始的吗?
在MySQL中,默认AUTO_INCREMENT的初始 值是1,每新增一条记录,字段值自动加1。设置自增属性(AUTO_INCREMENT)的时候,还可以指定第 一条插入记录的自增字段的值,这样新插入的记录的自增字段值从初始值开始递增,如在表中插入第一 条记录,同时指定id值为5,则以后插入的记录的id值就会从6开始往上增加。添加主键约束时,往往需要 设置字段自动增加属性。
面试4、并不是每个表都可以任意选择存储引擎?
外键约束(FOREIGN KEY)不能跨引擎使用。 MySQL支持多种存储引擎,每一个表都可以指定一个不同的存储引擎,需要注意的是:外键约束是用来 保证数据的参照完整性的,如果表之间需要关联外键,却指定了不同的存储引擎,那么这些表之间是不 能创建外键约束的。所以说,存储引擎的选择也不完全是随意的。
视图
常见的数据库对象:
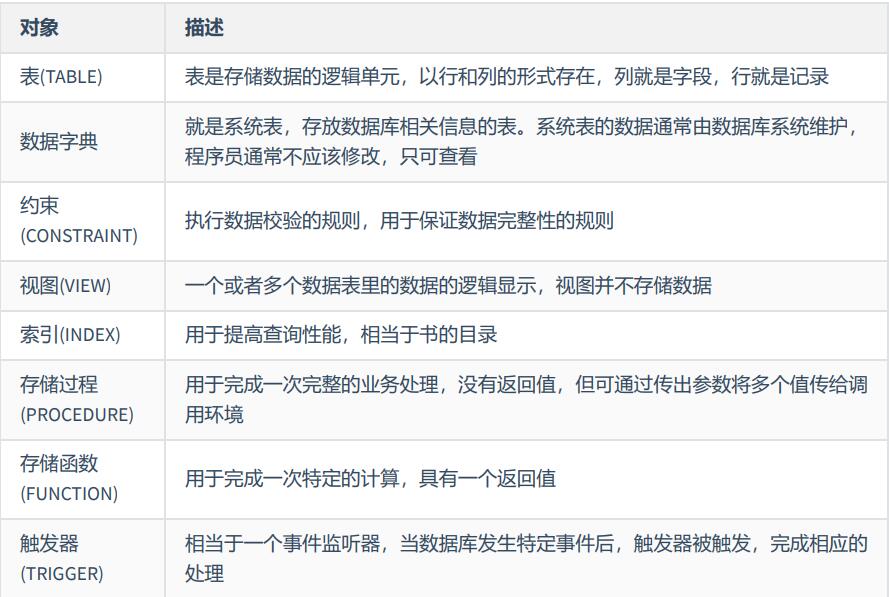
视图可以历届为存储起来的select语句。
#第14章_视图(View)
/*
1. 视图的理解
① 视图,可以看做是一个虚拟表,本身是不存储数据的。
视图的本质,就可以看做是存储起来的SELECT语句
② 视图中SELECT语句中涉及到的表,称为基表
③ 针对视图做DML操作,会影响到对应的基表中的数据。反之亦然。
④ 视图本身的删除,不会导致基表中数据的删除。
⑤ 视图的应用场景:针对于小型项目,不推荐使用视图。针对于大型项目,可以考虑使用视图。
⑥ 视图的优点:简化查询; 控制数据的访问
*/
#2. 如何创建视图
#准备工作
CREATE DATABASE dbtest14;
USE dbtest14;
CREATE TABLE emps
AS
SELECT *
FROM atguigudb.`employees`;
CREATE TABLE depts
AS
SELECT *
FROM atguigudb.`departments`;
SELECT * FROM emps;
SELECT * FROM depts;
DESC emps;
DESC atguigudb.employees;
#2.1 针对于单表
#情况1:视图中的字段与基表的字段有对应关系
CREATE VIEW vu_emp1
AS
SELECT employee_id,last_name,salary
FROM emps;
SELECT * FROM vu_emp1;
#确定视图中字段名的方式1:
CREATE VIEW vu_emp2
AS
SELECT employee_id emp_id,last_name lname,salary #查询语句中字段的别名会作为视图中字段的名称出现
FROM emps
WHERE salary > 8000;
#确定视图中字段名的方式2:
CREATE VIEW vu_emp3(emp_id,NAME,monthly_sal) #小括号内字段个数与SELECT中字段个数相同
AS
SELECT employee_id,last_name,salary
FROM emps
WHERE salary > 8000;
SELECT * FROM vu_emp3;
#情况2:视图中的字段在基表中可能没有对应的字段
CREATE VIEW vu_emp_sal
AS
SELECT department_id,AVG(salary) avg_sal
FROM emps
WHERE department_id IS NOT NULL
GROUP BY department_id;
SELECT * FROM vu_emp_sal;
#2.2 针对于多表
CREATE VIEW vu_emp_dept
AS
SELECT e.employee_id,e.department_id,d.department_name
FROM emps e JOIN depts d
ON e.`department_id` = d.`department_id`;
SELECT * FROM vu_emp_dept;
#利用视图对数据进行格式化
CREATE VIEW vu_emp_dept1
AS
SELECT CONCAT(e.last_name,'(',d.department_name,')') emp_info
FROM emps e JOIN depts d
ON e.`department_id` = d.`department_id`;
SELECT * FROM vu_emp_dept1;
#2.3 基于视图创建视图
CREATE VIEW vu_emp4
AS
SELECT employee_id,last_name
FROM vu_emp1;
SELECT * FROM vu_emp4;
#3. 查看视图
# 语法1:查看数据库的表对象、视图对象
SHOW TABLES;
#语法2:查看视图的结构
DESCRIBE vu_emp1;
#语法3:查看视图的属性信息
SHOW TABLE STATUS LIKE 'vu_emp1';
#语法4:查看视图的详细定义信息
SHOW CREATE VIEW vu_emp1;
#4."更新"视图中的数据
#4.1 一般情况,可以更新视图的数据
SELECT * FROM vu_emp1;
SELECT employee_id,last_name,salary
FROM emps;
#更新视图的数据,会导致基表中数据的修改
UPDATE vu_emp1
SET salary = 20000
WHERE employee_id = 101;
#同理,更新表中的数据,也会导致视图中的数据的修改
UPDATE emps
SET salary = 10000
WHERE employee_id = 101;
#删除视图中的数据,也会导致表中的数据的删除
DELETE FROM vu_emp1
WHERE employee_id = 101;
SELECT employee_id,last_name,salary
FROM emps
WHERE employee_id = 101;
#4.2 不能更新视图中的数据
SELECT * FROM vu_emp_sal;
#更新失败
UPDATE vu_emp_sal
SET avg_sal = 5000
WHERE department_id = 30;
#删除失败
DELETE FROM vu_emp_sal
WHERE department_id = 30;
#5. 修改视图
DESC vu_emp1;
#方式1
CREATE OR REPLACE VIEW vu_emp1
AS
SELECT employee_id,last_name,salary,email
FROM emps
WHERE salary > 7000;
#方式2
ALTER VIEW vu_emp1
AS
SELECT employee_id,last_name,salary,email,hire_date
FROM emps;
#6. 删除视图
SHOW TABLES;
DROP VIEW vu_emp4;
DROP VIEW IF EXISTS vu_emp2,vu_emp3;视图优点
操作简单
将经常使用的查询操作定义为视图,可以使开发人员不需要关心视图对应的数据表的结构、表与表之间 的关联关系,也不需要关心数据表之间的业务逻辑和查询条件,而只需要简单地操作视图即可,极大简 化了开发人员对数据库的操作。
减少数据冗余
视图跟实际数据表不一样,它存储的是查询语句。所以,在使用的时候,我们要通过定义视图的查询语 句来获取结果集。而视图本身不存储数据,不占用数据存储的资源,减少了数据冗余。
数据安全
MySQL将用户对数据的 访问限制 在某些数据的结果集上,而这些数据的结果集可以使用视图来实现。用 户不必直接查询或操作数据表。这也可以理解为视图具有 隔离性 。视图相当于在用户和实际的数据表之 间加了一层虚拟表。同时,MySQL可以根据权限将用户对数据的访问限制在某些视图上,用户不需要查询数据表,可以直接 通过视图获取数据表中的信息。这在一定程度上保障了数据表中数据的安全性。
适应灵活多变的需求
当业务系统的需求发生变化后,如果需要改动数据表的结构,则工作量相对较 大,可以使用视图来减少改动的工作量。这种方式在实际工作中使用得比较多。
能够分解复杂的查询逻辑
数据库中如果存在复杂的查询逻辑,则可以将问题进行分解,创建多个视图 获取数据,再将创建的多个视图结合起来,完成复杂的查询逻辑。
视图的不足:
- 如果实际数据表变更了,需要对视图进行维护
- 实际项目中,如果视图过多,会导致数据库维护成本的问题。
存储过程与存储函数
含义:存储过程的英文是 Stored Procedure 。它的思想很简单,就是一组经过 预先编译 的 SQL 语句 的封装。
执行过程:存储过程预先存储在 MySQL 服务器上,需要执行的时候,客户端只需要向服务器端发出调用 存储过程的命令,服务器端就可以把预先存储好的这一系列 SQL 语句全部执行。
好处:
1、简化操作,提高了sql语句的重用性,减少了开发程序员的压力
2、减少操作过程中的失误,提高效率
3、减少网络传输量(客户端不需要把所有的 SQL 语句通过网络发给服务器)
4、减少了 SQL 语句暴露在 网上的风险,也提高了数据查询的安全性
和视图、函数的对比:
它和视图有着同样的优点,清晰、安全,还可以减少网络传输量。不过它和视图不同,视图是 虚拟表 , 通常不对底层数据表直接操作,而存储过程是程序化的 SQL,可以 直接操作底层数据表 ,相比于面向集 合的操作方式,能够实现一些更复杂的数据处理。
一旦存储过程被创建出来,使用它就像使用函数一样简单,我们直接通过调用存储过程名即可。相较于 函数,存储过程是 没有返回值 的。
分类:
存储过程的参数类型可以是IN、OUT和INOUT。根据这点分类如下:
1、没有参数(无参数无返回)
2、仅仅带 IN 类型(有参数无返回)
3、仅仅带 OUT 类型(无参数有返 回)
4、既带 IN 又带 OUT(有参数有返回)
5、带 INOUT(有参数有返回)
注意:IN、OUT、INOUT 都可以在一个存储过程中带多个。
#第15章_存储过程与存储函数
#0.准备工作
CREATE DATABASE dbtest15;
USE dbtest15;
CREATE TABLE employees
AS
SELECT *
FROM atguigudb.`employees`;
CREATE TABLE departments
AS
SELECT * FROM atguigudb.`departments`;
SELECT * FROM employees;
SELECT * FROM departments;
#1. 创建存储过程
#类型1:无参数无返回值
#举例1:创建存储过程select_all_data(),查看 employees 表的所有数据
DELIMITER $
CREATE PROCEDURE select_all_data()
BEGIN
SELECT * FROM employees;
END $
DELIMITER ;
#2. 存储过程的调用
CALL select_all_data();
#举例2:创建存储过程avg_employee_salary(),返回所有员工的平均工资
DELIMITER //
CREATE PROCEDURE avg_employee_salary()
BEGIN
SELECT AVG(salary) FROM employees;
END //
DELIMITER ;
#调用
CALL avg_employee_salary();
#举例3:创建存储过程show_max_salary(),用来查看“emps”表的最高薪资值。
DELIMITER //
CREATE PROCEDURE show_max_salary()
BEGIN
SELECT MAX(salary)
FROM employees;
END //
DELIMITER ;
#调用
CALL show_max_salary();
#类型2:带 OUT
#举例4:创建存储过程show_min_salary(),查看“emps”表的最低薪资值。并将最低薪资
#通过OUT参数“ms”输出
DESC employees;
DELIMITER //
CREATE PROCEDURE show_min_salary(OUT ms DOUBLE)
BEGIN
SELECT MIN(salary) INTO ms
FROM employees;
END //
DELIMITER ;
#调用
CALL show_min_salary(@ms);
#查看变量值
SELECT @ms;
#类型3:带 IN
#举例5:创建存储过程show_someone_salary(),查看“emps”表的某个员工的薪资,
#并用IN参数empname输入员工姓名。
DELIMITER //
CREATE PROCEDURE show_someone_salary(IN empname VARCHAR(20))
BEGIN
SELECT salary FROM employees
WHERE last_name = empname;
END //
DELIMITER ;
#调用方式1
CALL show_someone_salary('Abel');
#调用方式2
SET @empname := 'Abel';
CALL show_someone_salary(@empname);
SELECT * FROM employees WHERE last_name = 'Abel';
#类型4:带 IN 和 OUT
#举例6:创建存储过程show_someone_salary2(),查看“emps”表的某个员工的薪资,
#并用IN参数empname输入员工姓名,用OUT参数empsalary输出员工薪资。
DELIMITER //
CREATE PROCEDURE show_someone_salary2(IN empname VARCHAR(20),OUT empsalary DECIMAL(10,2))
BEGIN
SELECT salary INTO empsalary
FROM employees
WHERE last_name = empname;
END //
DELIMITER ;
#调用
SET @empname = 'Abel';
CALL show_someone_salary2(@empname,@empsalary);
SELECT @empsalary;
#类型5:带 INOUT
#举例7:创建存储过程show_mgr_name(),查询某个员工领导的姓名,并用INOUT参数“empname”输入员工姓名,
#输出领导的姓名。
DESC employees;
DELIMITER $
CREATE PROCEDURE show_mgr_name(INOUT empname VARCHAR(25))
BEGIN
SELECT last_name INTO empname
FROM employees
WHERE employee_id = (
SELECT manager_id
FROM employees
WHERE last_name = empname
);
END $
DELIMITER ;
#调用
SET @empname := 'Abel';
CALL show_mgr_name(@empname);
SELECT @empname;
#2.存储函数
# 举例1:创建存储函数,名称为email_by_name(),参数定义为空,
#该函数查询Abel的email,并返回,数据类型为字符串型。
#若在创建存储函数中报错“ you might want to use the less safe
log_bin_trust_function_creators variable ”,有两种处理方法:
#方式1:加上必要的函数特性“[NOT] DETERMINISTIC”和“{CONTAINS SQL | NO SQL | READS SQL DATA |MODIFIES SQL DATA}”
#方式2: SET GLOBAL log_bin_trust_function_creators = 1;
DELIMITER //
CREATE FUNCTION email_by_name()
RETURNS VARCHAR(25)
DETERMINISTIC
CONTAINS SQL
READS SQL DATA
BEGIN
RETURN (SELECT email FROM employees WHERE last_name = 'Abel');
END //
DELIMITER ;
#调用
SELECT email_by_name();
SELECT email,last_name FROM employees WHERE last_name = 'Abel';
#举例2:创建存储函数,名称为email_by_id(),参数传入emp_id,该函数查询emp_id的email,
#并返回,数据类型为字符串型。
#创建函数前执行此语句,保证函数的创建会成功
SET GLOBAL log_bin_trust_function_creators = 1;
#声明函数
DELIMITER //
CREATE FUNCTION email_by_id(emp_id INT)
RETURNS VARCHAR(25)
BEGIN
RETURN (SELECT email FROM employees WHERE employee_id = emp_id);
END //
DELIMITER ;
#调用
SELECT email_by_id(101);
SET @emp_id := 102;
SELECT email_by_id(@emp_id);
#举例3:创建存储函数count_by_id(),参数传入dept_id,该函数查询dept_id部门的
#员工人数,并返回,数据类型为整型。
DELIMITER //
CREATE FUNCTION count_by_id(dept_id INT)
RETURNS INT
BEGIN
RETURN (SELECT COUNT(*) FROM employees WHERE department_id = dept_id);
END //
DELIMITER ;
#调用
SET @dept_id := 50;
SELECT count_by_id(@dept_id);
#3. 存储过程、存储函数的查看
#方式1. 使用SHOW CREATE语句查看存储过程和函数的创建信息
SHOW CREATE PROCEDURE show_mgr_name;
SHOW CREATE FUNCTION count_by_id;
#方式2. 使用SHOW STATUS语句查看存储过程和函数的状态信息
SHOW PROCEDURE STATUS;
SHOW PROCEDURE STATUS LIKE 'show_max_salary';
SHOW FUNCTION STATUS LIKE 'email_by_id';
#方式3.从information_schema.Routines表中查看存储过程和函数的信息
SELECT * FROM information_schema.Routines
WHERE ROUTINE_NAME='email_by_id' AND ROUTINE_TYPE = 'FUNCTION';
SELECT * FROM information_schema.Routines
WHERE ROUTINE_NAME='show_min_salary' AND ROUTINE_TYPE = 'PROCEDURE';
修改存储过程或函数,不影响存储过程或函数功能,只是修改相关特性。使用ALTER语句实现。
ALTER {PROCEDURE | FUNCTION} 存储过程或函数的名 [characteristic ...]其中,characteristic指定存储过程或函数的特性,其取值信息与创建存储过程、函数时的取值信息略有 不同。
{ CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT 'string'CONTAINS SQL ,表示子程序包含SQL语句,但不包含读或写数据的语句。
NO SQL ,表示子程序中不包含SQL语句。
READS SQL DATA ,表示子程序中包含读数据的语句。
MODIFIES SQL DATA ,表示子程序中包含写数据的语句。
SQL SECURITY { DEFINER | INVOKER } ,指明谁有权限来执行。
DEFINER ,表示只有定义者自己才能够执行。
INVOKER ,表示调用者可以执行。
COMMENT ‘string’ ,表示注释信息
#4.存储过程、函数的修改
ALTER PROCEDURE show_max_salary
SQL SECURITY INVOKER
COMMENT '查询最高工资';
#5. 存储过程、函数的删除
DROP FUNCTION IF EXISTS count_by_id;
DROP PROCEDURE IF EXISTS show_min_salary;存储函数和存储过程对比:
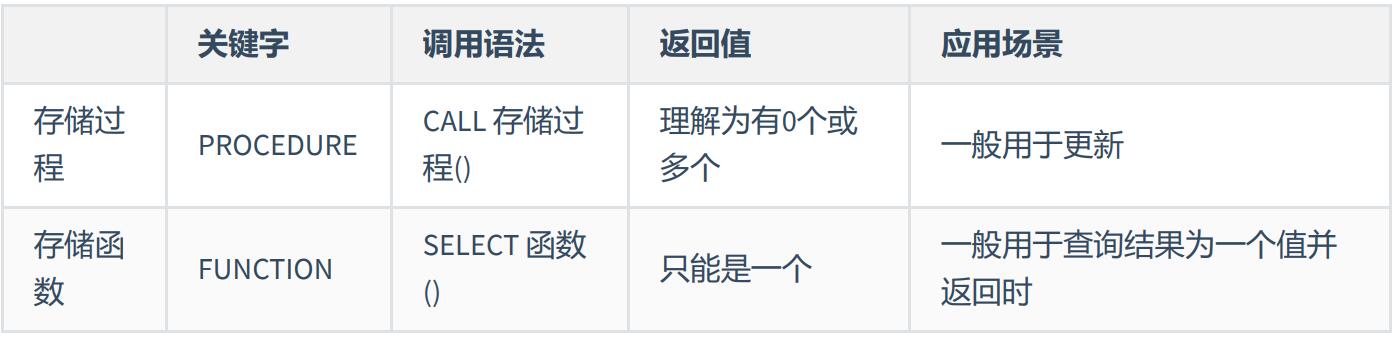
此外,存储函数可以放在查询语句中使用,存储过程不行。反之,存储过程的功能更加强大,包括能够 执行对表的操作(比如创建表,删除表等)和事务操作,这些功能是存储函数不具备的。
存储过程优点
1、存储过程可以一次编译多次使用。存储过程只在创建时进行编译,之后的使用都不需要重新编译, 这就提升了 SQL 的执行效率。
2、可以减少开发工作量。将代码 封装 成模块,实际上是编程的核心思想之一,这样可以把复杂的问题 拆解成不同的模块,然后模块之间可以 重复使用 ,在减少开发工作量的同时,还能保证代码的结构清 晰。
3、存储过程的安全性强。我们在设定存储过程的时候可以 设置对用户的使用权限 ,这样就和视图一样具 有较强的安全性。
4、可以减少网络传输量。因为代码封装到存储过程中,每次使用只需要调用存储过程即可,这样就减 少了网络传输量。
5、良好的封装性。在进行相对复杂的数据库操作时,原本需要使用一条一条的 SQL 语句,可能要连接 多次数据库才能完成的操作,现在变成了一次存储过程,只需要 连接一次即可 。
缺点:
基于上面这些优点,不少大公司都要求大型项目使用存储过程,比如微软、IBM 等公司。但是国内的阿 里并不推荐开发人员使用存储过程,这是为什么呢?
阿里开发规范
【强制】禁止使用存储过程,存储过程难以调试和扩展,更没有移植性。
1、可移植性差。存储过程不能跨数据库移植,比如在 MySQL、Oracle 和 SQL Server 里编写的存储过 程,在换成其他数据库时都需要重新编写。
2、调试困难。只有少数 DBMS 支持存储过程的调试。对于复杂的存储过程来说,开发和维护都不容 易。虽然也有一些第三方工具可以对存储过程进行调试,但要收费。
3、存储过程的版本管理很困难。比如数据表索引发生变化了,可能会导致存储过程失效。我们在开发 软件的时候往往需要进行版本管理,但是存储过程本身没有版本控制,版本迭代更新的时候很麻烦。
4、它不适合高并发的场景。高并发的场景需要减少数据库的压力,有时数据库会采用分库分表的方 式,而且对可扩展性要求很高,在这种情况下,存储过程会变得难以维护, 增加数据库的压力 ,显然就不适用了。
变量、流程控制与游标
#第16章_变量、流程控制与游标
#1. 变量
#1.1 变量: 系统变量(全局系统变量、会话系统变量) vs 用户自定义变量
#1.2 查看系统变量
#查询全局系统变量
SHOW GLOBAL VARIABLES; #617
#查询会话系统变量
SHOW SESSION VARIABLES; #640
SHOW VARIABLES; #默认查询的是会话系统变量
#查询部分系统变量
SHOW GLOBAL VARIABLES LIKE 'admin_%';
SHOW VARIABLES LIKE 'character_%';
#1.3 查看指定系统变量
SELECT @@global.max_connections;
SELECT @@global.character_set_client;
#错误:
SELECT @@global.pseudo_thread_id;
#错误:
SELECT @@session.max_connections;
SELECT @@session.character_set_client;
SELECT @@session.pseudo_thread_id;
SELECT @@character_set_client; #先查询会话系统变量,再查询全局系统变量
#1.4 修改系统变量的值
#全局系统变量:
#方式1:
SET @@global.max_connections = 161;
#方式2:
SET GLOBAL max_connections = 171;
#针对于当前的数据库实例是有效的,一旦重启mysql服务,就失效了。
#会话系统变量:
#方式1:
SET @@session.character_set_client = 'gbk';
#方式2:
SET SESSION character_set_client = 'gbk';
#针对于当前会话是有效的,一旦结束会话,重新建立起新的会话,就失效了。
#1.5 用户变量
/*
① 用户变量 : 会话用户变量 vs 局部变量
② 会话用户变量:使用"@"开头,作用域为当前会话。
③ 局部变量:只能使用在存储过程和存储函数中的。
*/
#1.6 会话用户变量
/*
① 变量的声明和赋值:
#方式1:“=”或“:=”
SET @用户变量 = 值;
SET @用户变量 := 值;
#方式2:“:=” 或 INTO关键字
SELECT @用户变量 := 表达式 [FROM 等子句];
SELECT 表达式 INTO @用户变量 [FROM 等子句];
② 使用
SELECT @变量名
*/
#准备工作
CREATE DATABASE dbtest16;
USE dbtest16;
CREATE TABLE employees
AS
SELECT * FROM atguigudb.`employees`;
CREATE TABLE departments
AS
SELECT * FROM atguigudb.`departments`;
SELECT * FROM employees;
SELECT * FROM departments;
#测试:
#方式1:
SET @m1 = 1;
SET @m2 := 2;
SET @sum := @m1 + @m2;
SELECT @sum;
#方式2:
SELECT @count := COUNT(*) FROM employees;
SELECT @count;
SELECT AVG(salary) INTO @avg_sal FROM employees;
SELECT @avg_sal;
#1.7 局部变量
/*
1、局部变量必须满足:
① 使用DECLARE声明
② 声明并使用在BEGIN ... END 中 (使用在存储过程、函数中)
③ DECLARE的方式声明的局部变量必须声明在BEGIN中的首行的位置。
2、声明格式:
DECLARE 变量名 类型 [default 值]; # 如果没有DEFAULT子句,初始值为NULL
3、赋值:
方式1:
SET 变量名=值;
SET 变量名:=值;
方式2:
SELECT 字段名或表达式 INTO 变量名 FROM 表;
4、使用
SELECT 局部变量名;
*/
#举例:
DELIMITER //
CREATE PROCEDURE test_var()
BEGIN
#1、声明局部变量
DECLARE a INT DEFAULT 0;
DECLARE b INT ;
#DECLARE a,b INT DEFAULT 0;
DECLARE emp_name VARCHAR(25);
#2、赋值
SET a = 1;
SET b := 2;
SELECT last_name INTO emp_name FROM employees WHERE employee_id = 101;
#3、使用
SELECT a,b,emp_name;
END //
DELIMITER ;
#调用存储过程
CALL test_var();
#举例1:声明局部变量,并分别赋值为employees表中employee_id为102的last_name和salary
DELIMITER //
CREATE PROCEDURE test_pro()
BEGIN
#声明
DECLARE emp_name VARCHAR(25);
DECLARE sal DOUBLE(10,2) DEFAULT 0.0;
#赋值
SELECT last_name,salary INTO emp_name,sal
FROM employees
WHERE employee_id = 102;
#使用
SELECT emp_name,sal;
END //
DELIMITER ;
#调用存储过程
CALL test_pro();
SELECT last_name,salary FROM employees
WHERE employee_id = 102;
#举例2:声明两个变量,求和并打印 (分别使用会话用户变量、局部变量的方式实现)
#方式1:使用会话用户变量
SET @v1 = 10;
SET @v2 := 20;
SET @result := @v1 + @v2;
#查看
SELECT @result;
#方式2:使用局部变量
DELIMITER //
CREATE PROCEDURE add_value()
BEGIN
#声明
DECLARE value1,value2,sum_val INT;
#赋值
SET value1 = 10;
SET value2 := 100;
SET sum_val = value1 + value2;
#使用
SELECT sum_val;
END //
DELIMITER ;
#调用存储过程
CALL add_value();
#举例3:创建存储过程“different_salary”查询某员工和他领导的薪资差距,并用IN参数emp_id接收员工id,
#用OUT参数dif_salary输出薪资差距结果。
DELIMITER //
CREATE PROCEDURE different_salary(IN emp_id INT,OUT dif_salary DOUBLE)
BEGIN
#分析:查询出emp_id员工的工资;查询出emp_id员工的管理者的id;查询管理者id的工资;计算两个工资的差值
#声明变量
DECLARE emp_sal DOUBLE DEFAULT 0.0; #记录员工的工资
DECLARE mgr_sal DOUBLE DEFAULT 0.0; #记录管理者的工资
DECLARE mgr_id INT DEFAULT 0; #记录管理者的id
#赋值
SELECT salary INTO emp_sal FROM employees WHERE employee_id = emp_id;
SELECT manager_id INTO mgr_id FROM employees WHERE employee_id = emp_id;
SELECT salary INTO mgr_sal FROM employees WHERE employee_id = mgr_id;
SET dif_salary = mgr_sal - emp_sal;
END //
DELIMITER ;
#调用存储过程
SET @emp_id := 103;
SET @dif_sal := 0;
CALL different_salary(@emp_id,@dif_sal);
SELECT @dif_sal;
SELECT * FROM employees;
#2. 定义条件和处理程序
#2.1 错误演示:
#错误代码: 1364
#Field 'email' doesnt have a default value
INSERT INTO employees(last_name)
VALUES('Tom');
DESC employees;
#错误演示:
DELIMITER //
CREATE PROCEDURE UpdateDataNoCondition()
BEGIN
SET @x = 1;
UPDATE employees SET email = NULL WHERE last_name = 'Abel';
SET @x = 2;
UPDATE employees SET email = 'aabbel' WHERE last_name = 'Abel';
SET @x = 3;
END //
DELIMITER ;
#调用存储过程
#错误代码: 1048
#Column 'email' cannot be null
CALL UpdateDataNoCondition();
SELECT @x;
#错误处理
#处理方式:处理方式有3个取值:CONTINUE、EXIT、UNDO。
#CONTINUE :表示遇到错误不处理,继续执行。
#EXIT :表示遇到错误马上退出。
#UNDO :表示遇到错误后撤回之前的操作。MySQL中暂时不支持这样的操作。错误类型(即条件)可以有如下取值:
#SQLSTATE '字符串错误码' :表示长度为5的sqlstate_value类型的错误代码;
#MySQL_error_code :匹配数值类型错误代码;
#错误名称 :表示DECLARE ... CONDITION定义的错误条件名称。
#SQLWARNING :匹配所有以01开头的SQLSTATE错误代码;
#NOT FOUND :匹配所有以02开头的SQLSTATE错误代码;
#SQLEXCEPTION :匹配所有没有被SQLWARNING或NOT FOUND捕获的SQLSTATE错误代码;
#处理语句:如果出现上述条件之一,则采用对应的处理方式,并执行指定的处理语句。语句可以是
#像“ SET 变量 = 值 ”这样的简单语句,也可以是使用 BEGIN ... END 编写的复合语句。
#2.2 定义条件
#格式:DECLARE 错误名称 CONDITION FOR 错误码(或错误条件)
#举例1:定义“Field_Not_Be_NULL”错误名与MySQL中违反非空约束的错误类型
#是“ERROR 1048 (23000)”对应。
#方式1:使用MySQL_error_code
DECLARE Field_Not_Be_NULL CONDITION FOR 1048;
#方式2:使用sqlstate_value
DECLARE Field_Not_Be_NULL CONDITION FOR SQLSTATE '23000';
#举例2:定义"ERROR 1148(42000)"错误,名称为command_not_allowed。
#方式1:使用MySQL_error_code
DECLARE command_not_allowed CONDITION FOR 1148;
#方式2:使用sqlstate_value
DECLARE command_not_allowed CONDITION FOR SQLSTATE '42000';
#2.3 定义处理程序
#格式:DECLARE 处理方式 HANDLER FOR 错误类型 处理语句
#举例:
#方法1:捕获sqlstate_value
DECLARE CONTINUE HANDLER FOR SQLSTATE '42S02' SET @info = 'NO_SUCH_TABLE';
#方法2:捕获mysql_error_value
DECLARE CONTINUE HANDLER FOR 1146 SET @info = 'NO_SUCH_TABLE';
#方法3:先定义条件,再调用
DECLARE no_such_table CONDITION FOR 1146;
DECLARE CONTINUE HANDLER FOR no_such_table SET @info = 'NO_SUCH_TABLE';
#方法4:使用SQLWARNING
DECLARE EXIT HANDLER FOR SQLWARNING SET @info = 'ERROR';
#方法5:使用NOT FOUND
DECLARE EXIT HANDLER FOR NOT FOUND SET @info = 'NO_SUCH_TABLE';
#方法6:使用SQLEXCEPTION
DECLARE EXIT HANDLER FOR SQLEXCEPTION SET @info = 'ERROR';
#2.4 案例的处理
DROP PROCEDURE UpdateDataNoCondition;
#重新定义存储过程,体现错误的处理程序
DELIMITER //
CREATE PROCEDURE UpdateDataNoCondition()
BEGIN
#声明处理程序
#处理方式1:
DECLARE CONTINUE HANDLER FOR 1048 SET @prc_value = -1;
#处理方式2:
#DECLARE CONTINUE HANDLER FOR sqlstate '23000' SET @prc_value = -1;
SET @x = 1;
UPDATE employees SET email = NULL WHERE last_name = 'Abel';
SET @x = 2;
UPDATE employees SET email = 'aabbel' WHERE last_name = 'Abel';
SET @x = 3;
END //
DELIMITER ;
#调用存储过程:
CALL UpdateDataNoCondition();
#查看变量:
SELECT @x,@prc_value;
#2.5 再举一个例子:
#创建一个名称为“InsertDataWithCondition”的存储过程
#① 准备工作
CREATE TABLE departments
AS
SELECT * FROM atguigudb.`departments`;
DESC departments;
ALTER TABLE departments
ADD CONSTRAINT uk_dept_name UNIQUE(department_id);
#② 定义存储过程:
DELIMITER //
CREATE PROCEDURE InsertDataWithCondition()
BEGIN
SET @x = 1;
INSERT INTO departments(department_name) VALUES('测试');
SET @x = 2;
INSERT INTO departments(department_name) VALUES('测试');
SET @x = 3;
END //
DELIMITER ;
#③ 调用
CALL InsertDataWithCondition();
SELECT @x; #2
#④ 删除此存储过程
DROP PROCEDURE IF EXISTS InsertDataWithCondition;
#⑤ 重新定义存储过程(考虑到错误的处理程序)
DELIMITER //
CREATE PROCEDURE InsertDataWithCondition()
BEGIN
#处理程序
#方式1:
#declare exit handler for 1062 set @pro_value = -1;
#方式2:
#declare exit handler for sqlstate '23000' set @pro_value = -1;
#方式3:
#定义条件
DECLARE duplicate_entry CONDITION FOR 1062;
DECLARE EXIT HANDLER FOR duplicate_entry SET @pro_value = -1;
SET @x = 1;
INSERT INTO departments(department_name) VALUES('测试');
SET @x = 2;
INSERT INTO departments(department_name) VALUES('测试');
SET @x = 3;
END //
DELIMITER ;
#调用
CALL InsertDataWithCondition();
SELECT @x,@pro_value;
#3. 流程控制
#3.1 分支结构之 IF
#举例1
DELIMITER //
CREATE PROCEDURE test_if()
BEGIN
#情况1:
#声明局部变量
#declare stu_name varchar(15);
#if stu_name is null
# then select 'stu_name is null';
#end if;
#情况2:二选一
#declare email varchar(25) default 'aaa';
#if email is null
# then select 'email is null';
#else
# select 'email is not null';
#end if;
#情况3:多选一
DECLARE age INT DEFAULT 20;
IF age > 40
THEN SELECT '中老年';
ELSEIF age > 18
THEN SELECT '青壮年';
ELSEIF age > 8
THEN SELECT '青少年';
ELSE
SELECT '婴幼儿';
END IF;
END //
DELIMITER ;
#调用
CALL test_if();
DROP PROCEDURE test_if;
#举例2:声明存储过程“update_salary_by_eid1”,定义IN参数emp_id,输入员工编号。
#判断该员工薪资如果低于8000元并且入职时间超过5年,就涨薪500元;否则就不变。
DELIMITER //
CREATE PROCEDURE update_salary_by_eid1(IN emp_id INT)
BEGIN
#声明局部变量
DECLARE emp_sal DOUBLE; #记录员工的工资
DECLARE hire_year DOUBLE; #记录员工入职公司的年头
#赋值
SELECT salary INTO emp_sal FROM employees WHERE employee_id = emp_id;
SELECT DATEDIFF(CURDATE(),hire_date)/365 INTO hire_year FROM employees WHERE employee_id = emp_id;
#判断
IF emp_sal < 8000 AND hire_year >= 5
THEN UPDATE employees SET salary = salary + 500 WHERE employee_id = emp_id;
END IF;
END //
DELIMITER ;
#调用存储过程
CALL update_salary_by_eid1(104);
SELECT DATEDIFF(CURDATE(),hire_date)/365, employee_id,salary
FROM employees
WHERE salary < 8000 AND DATEDIFF(CURDATE(),hire_date)/365 >= 5;
DROP PROCEDURE update_salary_by_eid1;
#举例3:声明存储过程“update_salary_by_eid2”,定义IN参数emp_id,输入员工编号。
#判断该员工薪资如果低于9000元并且入职时间超过5年,就涨薪500元;否则就涨薪100元。
DELIMITER //
CREATE PROCEDURE update_salary_by_eid2(IN emp_id INT)
BEGIN
#声明局部变量
DECLARE emp_sal DOUBLE; #记录员工的工资
DECLARE hire_year DOUBLE; #记录员工入职公司的年头
#赋值
SELECT salary INTO emp_sal FROM employees WHERE employee_id = emp_id;
SELECT DATEDIFF(CURDATE(),hire_date)/365 INTO hire_year FROM employees WHERE employee_id = emp_id;
#判断
IF emp_sal < 9000 AND hire_year >= 5
THEN UPDATE employees SET salary = salary + 500 WHERE employee_id = emp_id;
ELSE
UPDATE employees SET salary = salary + 100 WHERE employee_id = emp_id;
END IF;
END //
DELIMITER ;
#调用
CALL update_salary_by_eid2(103);
CALL update_salary_by_eid2(104);
SELECT * FROM employees
WHERE employee_id IN (103,104);
#举例4:声明存储过程“update_salary_by_eid3”,定义IN参数emp_id,输入员工编号。
#判断该员工薪资如果低于9000元,就更新薪资为9000元;薪资如果大于等于9000元且
#低于10000的,但是奖金比例为NULL的,就更新奖金比例为0.01;其他的涨薪100元。
DELIMITER //
CREATE PROCEDURE update_salary_by_eid3(IN emp_id INT)
BEGIN
#声明变量
DECLARE emp_sal DOUBLE; #记录员工工资
DECLARE bonus DOUBLE; #记录员工的奖金率
#赋值
SELECT salary INTO emp_sal FROM employees WHERE employee_id = emp_id;
SELECT commission_pct INTO bonus FROM employees WHERE employee_id = emp_id;
#判断
IF emp_sal < 9000
THEN UPDATE employees SET salary = 9000 WHERE employee_id = emp_id;
ELSEIF emp_sal < 10000 AND bonus IS NULL
THEN UPDATE employees SET commission_pct = 0.01 WHERE employee_id = emp_id;
ELSE
UPDATE employees SET salary = salary + 100 WHERE employee_id = emp_id;
END IF;
END //
DELIMITER ;
#调用
CALL update_salary_by_eid3(102);
CALL update_salary_by_eid3(103);
CALL update_salary_by_eid3(104);
SELECT *
FROM employees
WHERE employee_id IN (102,103,104);
##3.2 分支结构之case
#举例1:基本使用
DELIMITER //
CREATE PROCEDURE test_case()
BEGIN
#演示1:case ... when ...then ...
/*
declare var int default 2;
case var
when 1 then select 'var = 1';
when 2 then select 'var = 2';
when 3 then select 'var = 3';
else select 'other value';
end case;
*/
#演示2:case when ... then ....
DECLARE var1 INT DEFAULT 10;
CASE
WHEN var1 >= 100 THEN SELECT '三位数';
WHEN var1 >= 10 THEN SELECT '两位数';
ELSE SELECT '个数位';
END CASE;
END //
DELIMITER ;
#调用
CALL test_case();
DROP PROCEDURE test_case;
#举例2:声明存储过程“update_salary_by_eid4”,定义IN参数emp_id,输入员工编号。
#判断该员工薪资如果低于9000元,就更新薪资为9000元;薪资大于等于9000元且低于10000的,
#但是奖金比例为NULL的,就更新奖金比例为0.01;其他的涨薪100元。
DELIMITER //
CREATE PROCEDURE update_salary_by_eid4(IN emp_id INT)
BEGIN
#局部变量的声明
DECLARE emp_sal DOUBLE; #记录员工的工资
DECLARE bonus DOUBLE; #记录员工的奖金率
#局部变量的赋值
SELECT salary INTO emp_sal FROM employees WHERE employee_id = emp_id;
SELECT commission_pct INTO bonus FROM employees WHERE employee_id = emp_id;
CASE
WHEN emp_sal < 9000 THEN UPDATE employees SET salary = 9000 WHERE employee_id = emp_id;
WHEN emp_sal < 10000 AND bonus IS NULL THEN UPDATE employees SET commission_pct = 0.01
WHERE employee_id = emp_id;
ELSE UPDATE employees SET salary = salary + 100 WHERE employee_id = emp_id;
END CASE;
END //
DELIMITER ;
#调用
CALL update_salary_by_eid4(103);
CALL update_salary_by_eid4(104);
CALL update_salary_by_eid4(105);
SELECT *
FROM employees
WHERE employee_id IN (103,104,105);
#举例3:声明存储过程update_salary_by_eid5,定义IN参数emp_id,输入员工编号。
#判断该员工的入职年限,如果是0年,薪资涨50;如果是1年,薪资涨100;
#如果是2年,薪资涨200;如果是3年,薪资涨300;如果是4年,薪资涨400;其他的涨薪500。
DELIMITER //
CREATE PROCEDURE update_salary_by_eid5(IN emp_id INT)
BEGIN
#声明局部变量
DECLARE hire_year INT; #记录员工入职公司的总时间(单位:年)
#赋值
SELECT ROUND(DATEDIFF(CURDATE(),hire_date) / 365) INTO hire_year
FROM employees WHERE employee_id = emp_id;
#判断
CASE hire_year
WHEN 0 THEN UPDATE employees SET salary = salary + 50 WHERE employee_id = emp_id;
WHEN 1 THEN UPDATE employees SET salary = salary + 100 WHERE employee_id = emp_id;
WHEN 2 THEN UPDATE employees SET salary = salary + 200 WHERE employee_id = emp_id;
WHEN 3 THEN UPDATE employees SET salary = salary + 300 WHERE employee_id = emp_id;
WHEN 4 THEN UPDATE employees SET salary = salary + 400 WHERE employee_id = emp_id;
ELSE UPDATE employees SET salary = salary + 500 WHERE employee_id = emp_id;
END CASE;
END //
DELIMITER ;
#调用
CALL update_salary_by_eid5(101);
SELECT *
FROM employees
DROP PROCEDURE update_salary_by_eid5;
#4.1 循环结构之LOOP
/*
[loop_label:] LOOP
循环执行的语句
END LOOP [loop_label]
*/
#举例1:
DELIMITER //
CREATE PROCEDURE test_loop()
BEGIN
#声明局部变量
DECLARE num INT DEFAULT 1;
loop_label:LOOP
#重新赋值
SET num = num + 1;
#可以考虑某个代码程序反复执行。(略)
IF num >= 10 THEN LEAVE loop_label;
END IF;
END LOOP loop_label;
#查看num
SELECT num;
END //
DELIMITER ;
#调用
CALL test_loop();
#举例2:当市场环境变好时,公司为了奖励大家,决定给大家涨工资。
#声明存储过程“update_salary_loop()”,声明OUT参数num,输出循环次数。
#存储过程中实现循环给大家涨薪,薪资涨为原来的1.1倍。直到全公司的平
#均薪资达到12000结束。并统计循环次数。
DELIMITER //
CREATE PROCEDURE update_salary_loop(OUT num INT)
BEGIN
#声明变量
DECLARE avg_sal DOUBLE ; #记录员工的平均工资
DECLARE loop_count INT DEFAULT 0;#记录循环的次数
#① 初始化条件
#获取员工的平均工资
SELECT AVG(salary) INTO avg_sal FROM employees;
loop_lab:LOOP
#② 循环条件
#结束循环的条件
IF avg_sal >= 12000
THEN LEAVE loop_lab;
END IF;
#③ 循环体
#如果低于12000,更新员工的工资
UPDATE employees SET salary = salary * 1.1;
#④ 迭代条件
#更新avg_sal变量的值
SELECT AVG(salary) INTO avg_sal FROM employees;
#记录循环次数
SET loop_count = loop_count + 1;
END LOOP loop_lab;
#给num赋值
SET num = loop_count;
END //
DELIMITER ;
SELECT AVG(salary) FROM employees;
CALL update_salary_loop(@num);
SELECT @num;
#4.2 循环结构之WHILE
/*
[while_label:] WHILE 循环条件 DO
循环体
END WHILE [while_label];
*/
#举例1:
DELIMITER //
CREATE PROCEDURE test_while()
BEGIN
#初始化条件
DECLARE num INT DEFAULT 1;
#循环条件
WHILE num <= 10 DO
#循环体(略)
#迭代条件
SET num = num + 1;
END WHILE;
#查询
SELECT num;
END //
DELIMITER ;
#调用
CALL test_while();
#举例2:市场环境不好时,公司为了渡过难关,决定暂时降低大家的薪资。
#声明存储过程“update_salary_while()”,声明OUT参数num,输出循环次数。
#存储过程中实现循环给大家降薪,薪资降为原来的90%。直到全公司的平均薪资
#达到5000结束。并统计循环次数。
DELIMITER //
CREATE PROCEDURE update_salary_while(OUT num INT)
BEGIN
#声明变量
DECLARE avg_sal DOUBLE ; #记录平均工资
DECLARE while_count INT DEFAULT 0; #记录循环次数
#赋值
SELECT AVG(salary) INTO avg_sal FROM employees;
WHILE avg_sal > 5000 DO
UPDATE employees SET salary = salary * 0.9 ;
SET while_count = while_count + 1;
SELECT AVG(salary) INTO avg_sal FROM employees;
END WHILE;
#给num赋值
SET num = while_count;
END //
DELIMITER ;
#调用
CALL update_salary_while(@num);
SELECT @num;
SELECT AVG(salary) FROM employees;
#4.3 循环结构之REPEAT
/*
[repeat_label:] REPEAT
循环体的语句
UNTIL 结束循环的条件表达式
END REPEAT [repeat_label]
*/
#举例1:
DELIMITER //
CREATE PROCEDURE test_repeat()
BEGIN
#声明变量
DECLARE num INT DEFAULT 1;
REPEAT
SET num = num + 1;
UNTIL num >= 10
END REPEAT;
#查看
SELECT num;
END //
DELIMITER ;
#调用
CALL test_repeat();
#举例2:当市场环境变好时,公司为了奖励大家,决定给大家涨工资。
#声明存储过程“update_salary_repeat()”,声明OUT参数num,输出循环次数。
#存储过程中实现循环给大家涨薪,薪资涨为原来的1.15倍。直到全公司的平均
#薪资达到13000结束。并统计循环次数。
DELIMITER //
CREATE PROCEDURE update_salary_repeat(OUT num INT)
BEGIN
#声明变量
DECLARE avg_sal DOUBLE ; #记录平均工资
DECLARE repeat_count INT DEFAULT 0; #记录循环次数
#赋值
SELECT AVG(salary) INTO avg_sal FROM employees;
REPEAT
UPDATE employees SET salary = salary * 1.15;
SET repeat_count = repeat_count + 1;
SELECT AVG(salary) INTO avg_sal FROM employees;
UNTIL avg_sal >= 13000
END REPEAT;
#给num赋值
SET num = repeat_count;
END //
DELIMITER ;
#调用
CALL update_salary_repeat(@num);
SELECT @num;
SELECT AVG(salary) FROM employees;
/*
凡是循环结构,一定具备4个要素:
1. 初始化条件
2. 循环条件
3. 循环体
4. 迭代条件
*/
#5.1 LEAVE的使用
/*
**举例1:**创建存储过程 “leave_begin()”,声明INT类型的IN参数num。给BEGIN...END加标记名,
并在BEGIN...END中使用IF语句判断num参数的值。
- 如果num<=0,则使用LEAVE语句退出BEGIN...END;
- 如果num=1,则查询“employees”表的平均薪资;
- 如果num=2,则查询“employees”表的最低薪资;
- 如果num>2,则查询“employees”表的最高薪资。
IF语句结束后查询“employees”表的总人数。
*/
DELIMITER //
CREATE PROCEDURE leave_begin(IN num INT)
begin_label:BEGIN
IF num <= 0
THEN LEAVE begin_label;
ELSEIF num = 1
THEN SELECT AVG(salary) FROM employees;
ELSEIF num = 2
THEN SELECT MIN(salary) FROM employees;
ELSE
SELECT MAX(salary) FROM employees;
END IF;
#查询总人数
SELECT COUNT(*) FROM employees;
END //
DELIMITER ;
#调用
CALL leave_begin(1);
#举例2:当市场环境不好时,公司为了渡过难关,决定暂时降低大家的薪资。
#声明存储过程“leave_while()”,声明OUT参数num,输出循环次数,存储过程中使用WHILE
#循环给大家降低薪资为原来薪资的90%,直到全公司的平均薪资小于等于10000,并统计循环次数。
DELIMITER //
CREATE PROCEDURE leave_while(OUT num INT)
BEGIN
#
DECLARE avg_sal DOUBLE;#记录平均工资
DECLARE while_count INT DEFAULT 0; #记录循环次数
SELECT AVG(salary) INTO avg_sal FROM employees; #① 初始化条件
while_label:WHILE TRUE DO #② 循环条件
#③ 循环体
IF avg_sal <= 10000 THEN
LEAVE while_label;
END IF;
UPDATE employees SET salary = salary * 0.9;
SET while_count = while_count + 1;
#④ 迭代条件
SELECT AVG(salary) INTO avg_sal FROM employees;
END WHILE;
#赋值
SET num = while_count;
END //
DELIMITER ;
#调用
CALL leave_while(@num);
SELECT @num;
SELECT AVG(salary) FROM employees;
#5.2 ITERATE的使用
/*
举例: 定义局部变量num,初始值为0。循环结构中执行num + 1操作。
- 如果num < 10,则继续执行循环;
- 如果num > 15,则退出循环结构;
*/
DELIMITER //
CREATE PROCEDURE test_iterate()
BEGIN
DECLARE num INT DEFAULT 0;
loop_label:LOOP
#赋值
SET num = num + 1;
IF num < 10
THEN ITERATE loop_label;
ELSEIF num > 15
THEN LEAVE loop_label;
END IF;
SELECT '啦啦啦啦啦啦!';
END LOOP;
END //
DELIMITER ;
CALL test_iterate();
SELECT * FROM employees;
#6. 游标的使用
/*
游标使用的步骤:
① 声明游标
② 打开游标
③ 使用游标(从游标中获取数据)
④ 关闭游标
*/
#举例:创建存储过程“get_count_by_limit_total_salary()”,声明IN参数 limit_total_salary,
#DOUBLE类型;声明OUT参数total_count,INT类型。函数的功能可以实现累加薪资最高的几个员工的薪资值,
#直到薪资总和达到limit_total_salary参数的值,返回累加的人数给total_count。
DELIMITER //
CREATE PROCEDURE get_count_by_limit_total_salary(IN limit_total_salary DOUBLE,OUT total_count INT)
BEGIN
#声明局部变量
DECLARE sum_sal DOUBLE DEFAULT 0.0; #记录累加的工资总额
DECLARE emp_sal DOUBLE; #记录每一个员工的工资
DECLARE emp_count INT DEFAULT 0;#记录累加的人数
#1.声明游标
DECLARE emp_cursor CURSOR FOR SELECT salary FROM employees ORDER BY salary DESC;
#2.打开游标
OPEN emp_cursor;
REPEAT
#3.使用游标
FETCH emp_cursor INTO emp_sal;
SET sum_sal = sum_sal + emp_sal;
SET emp_count = emp_count + 1;
UNTIL sum_sal >= limit_total_salary
END REPEAT;
SET total_count = emp_count;
#4.关闭游标
CLOSE emp_cursor;
END //
DELIMITER ;
#调用
CALL get_count_by_limit_total_salary(200000,@total_count);
SELECT @total_count;
在MySQL数据库中,全局变量可以通过SET GLOBAL语句来设置。例如,设置服务器语句超时的限制,可 以通过设置系统变量max_execution_time来实现:
SET GLOBAL MAX_EXECUTION_TIME=2000;使用SET GLOBAL语句设置的变量值只会 临时生效 。 数据库重启 后,服务器又会从MySQL配置文件中读取 变量的默认值。 MySQL 8.0版本新增了 SET PERSIST 命令。例如,设置服务器的最大连接数为1000:
SET PERSIST global max_connections = 1000;MySQL会将该命令的配置保存到数据目录下的 mysqld-auto.cnf 文件中,下次启动时会读取该文件,用 其中的配置来覆盖默认的配置文件。
查看全局变量max_connections的值
show variables like '%max_connections%';设置全局变量max_connections的值:
set persist max_connections=1000;重启MySQL服务器 ,再次查询max_connections的值:
show variables like '%max_connections%';触发器
#0.准备工作
CREATE DATABASE dbtest17;
USE dbtest17;
#1. 创建触发器
#举例1:
#① 创建数据表
CREATE TABLE test_trigger (
id INT PRIMARY KEY AUTO_INCREMENT,
t_note VARCHAR(30)
);
CREATE TABLE test_trigger_log (
id INT PRIMARY KEY AUTO_INCREMENT,
t_log VARCHAR(30)
);
#② 查看表数据
SELECT * FROM test_trigger;
SELECT * FROM test_trigger_log;
#③ 创建触发器
#创建名称为before_insert_test_tri的触发器,向test_trigger数据表插入数据之前,
#向test_trigger_log数据表中插入before_insert的日志信息。
DELIMITER //
CREATE TRIGGER before_insert_test_tri
BEFORE INSERT ON test_trigger
FOR EACH ROW
BEGIN
INSERT INTO test_trigger_log(t_log)
VALUES('before insert...');
END //
DELIMITER ;
#④ 测试
INSERT INTO test_trigger(t_note)
VALUES('Tom...');
SELECT * FROM test_trigger;
SELECT * FROM test_trigger_log;
#举例2:
#创建名称为after_insert_test_tri的触发器,向test_trigger数据表插入数据之后,
#向test_trigger_log数据表中插入after_insert的日志信息。
DELIMITER $
CREATE TRIGGER after_insert_test_tri
AFTER INSERT ON test_trigger
FOR EACH ROW
BEGIN
INSERT INTO test_trigger_log(t_log)
VALUES('after insert...');
END $
DELIMITER ;
#测试
INSERT INTO test_trigger(t_note)
VALUES('Jerry2...');
SELECT * FROM test_trigger;
SELECT * FROM test_trigger_log;
#举例3:
#定义触发器“salary_check_trigger”,基于员工表“employees”的INSERT事件,
#在INSERT之前检查将要添加的新员工薪资是否大于他领导的薪资,如果大于领导薪资,
#则报sqlstate_value为'HY000'的错误,从而使得添加失败。
#准备工作
CREATE TABLE employees
AS
SELECT * FROM atguigudb.`employees`;
CREATE TABLE departments
AS
SELECT * FROM atguigudb.`departments`;
DESC employees;
#创建触发器
DELIMITER //
CREATE TRIGGER salary_check_trigger
BEFORE INSERT ON employees
FOR EACH ROW
BEGIN
#查询到要添加的数据的manager的薪资
DECLARE mgr_sal DOUBLE;
SELECT salary INTO mgr_sal FROM employees
WHERE employee_id = NEW.manager_id;
IF NEW.salary > mgr_sal
THEN SIGNAL SQLSTATE 'HY000' SET MESSAGE_TEXT = '薪资高于领导薪资错误';
END IF;
END //
DELIMITER ;
#测试
DESC employees;
#添加成功:依然触发了触发器salary_check_trigger的执行
INSERT INTO employees(employee_id,last_name,email,hire_date,job_id,salary,manager_id)
VALUES(300,'Tom','tom@126.com',CURDATE(),'AD_VP',8000,103);
#添加失败
INSERT INTO employees(employee_id,last_name,email,hire_date,job_id,salary,manager_id)
VALUES(301,'Tom1','tom1@126.com',CURDATE(),'AD_VP',10000,103);
SELECT * FROM employees;
#2. 查看触发器
#① 查看当前数据库的所有触发器的定义
SHOW TRIGGERS;
#② 方式2:查看当前数据库中某个触发器的定义
SHOW CREATE TRIGGER salary_check_trigger;
#③ 方式3:从系统库information_schema的TRIGGERS表中查询“salary_check_trigger”触发器的信息。
SELECT * FROM information_schema.TRIGGERS;
#3. 删除触发器
DROP TRIGGER IF EXISTS after_insert_test_tri;
Mysql8新特性
新特性1:窗口函数
窗口函数的语法结构是:
函数 OVER([PARTITION BY 字段名 ORDER BY 字段名 ASC|DESC])或者是:
函数 OVER 窗口名 … WINDOW 窗口名 AS ([PARTITION BY 字段名 ORDER BY 字段名 ASC|DESC])OVER 关键字指定函数窗口的范围。
如果省略后面括号中的内容,则窗口会包含满足WHERE条件的所有记录,窗口函数会基于所 有满足WHERE条件的记录进行计算。
如果OVER关键字后面的括号不为空,则可以使用如下语法设置窗口。
窗口名:为窗口设置一个别名,用来标识窗口。
PARTITION BY子句:指定窗口函数按照哪些字段进行分组。分组后,窗口函数可以在每个分组中分 别执行。
ORDER BY子句:指定窗口函数按照哪些字段进行排序。执行排序操作使窗口函数按照排序后的数据 记录的顺序进行编号。
FRAME子句:为分区中的某个子集定义规则,可以用来作为滑动窗口使用。
序号函数
1.ROW_NUMBER()函数
ROW_NUMBER()函数能够对数据中的序号进行顺序显示。
举例:查询 goods 数据表中每个商品分类下价格降序排列的各个商品信息。
SELECT ROW_NUMBER() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,id, category_id, category, NAME, price, stockFROM goods;举例:查询 goods 数据表中每个商品分类下价格最高的3种商品信息。
SELECT * FROM (SELECT ROW_NUMBER() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,id, category_id, category, NAME, price, stock FROM goods) t WHERE row_num <= 3;2.RANK()函数
使用RANK()函数能够对序号进行并列排序,并且会跳过重复的序号,比如序号为1、1、3。
举例:使用RANK()函数获取 goods 数据表中各类别的价格从高到低排序的各商品信息。
SELECT RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,id, category_id, category, NAME, price, stock FROM goods;举例:使用RANK()函数获取 goods 数据表中类别为“女装/女士精品”的价格最高的4款商品信息。
SELECT RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,id, category_id, category, NAME, price, stock FROM goods) t WHERE category_id = 1 AND row_num <= 4;
3.DENSE_RANK()函数
DENSE_RANK()函数对序号进行并列排序,并且不会跳过重复的序号,比如序号为1、1、2。
举例:使用DENSE_RANK()函数获取 goods 数据表中各类别的价格从高到低排序的各商品信息。
SELECT DENSE_RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,id, category_id, category, NAME,price, stock FROM goods;举例:使用DENSE_RANK()函数获取 goods 数据表中类别为“女装/女士精品”的价格最高的4款商品信息。
SELECT * FROM( SELECT DENSE_RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,id, category_id, category, NAME, price, stock FROM goods) t WHERE category_id = 1 AND row_num <= 3;2. 分布函数
1.PERCENT_RANK()函数
PERCENT_RANK()函数是等级值百分比函数。按照如下方式进行计算。
(rank - 1) / (rows - 1)其中,rank的值为使用RANK()函数产生的序号,rows的值为当前窗口的总记录数。
举例:计算 goods 数据表中名称为“女装/女士精品”的类别下的商品的PERCENT_RANK值。
#写法一:
SELECT RANK() OVER (PARTITION BY category_id ORDER BY price DESC) AS r,PERCENT_RANK() OVER (PARTITION BY category_id ORDER BY price DESC) AS pr,id, category_id, category, NAME, price, stock FROM goods WHERE category_id = 1;
#写法二:
SELECT RANK() OVER w AS r, PERCENT_RANK() OVER w AS pr, id, category_id, category, NAME, price, stock FROM goods WHERE category_id = 1 WINDOW w AS (PARTITION BY category_id ORDER BY price DESC);2.CUME_DIST()函数
CUME_DIST()函数主要用于查询小于或等于某个值的比例。
举例:查询goods数据表中小于或等于当前价格的比例。
SELECT CUME_DIST() OVER(PARTITION BY category_id ORDER BY price ASC) AS cd,id, category, NAME, price FROM goods;3. 前后函数
1.LAG(expr,n)函数
LAG(expr,n)函数返回当前行的前n行的expr的值。
举例:查询goods数据表中前一个商品价格与当前商品价格的差值。
SELECT id, category, NAME, price, pre_price, price - re_price AS diff_price FROM (SELECT id, category, NAME, price,LAG(price,1) OVER w AS pre_price FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price)) t;2.LEAD(expr,n)函数
LEAD(expr,n)函数返回当前行的后n行的expr的值。
举例:查询goods数据表中后一个商品价格与当前商品价格的差值。
SELECT id, category, NAME, behind_price, price,behind_price - price AS diff_price FROM( SELECT id, category, NAME, price,LEAD(price, 1) OVER w AS behind_price FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price)) t;4. 首尾函数
1.FIRST_VALUE(expr)函数
FIRST_VALUE(expr)函数返回第一个expr的值。
举例:按照价格排序,查询第1个商品的价格信息。
SELECT id, category, NAME, price, stock,FIRST_VALUE(price) OVER w AS first_price FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);2.LAST_VALUE(expr)函数
LAST_VALUE(expr)函数返回最后一个expr的值。
举例:按照价格排序,查询最后一个商品的价格信息。
SELECT id, category, NAME, price, stock,LAST_VALUE(price) OVER w AS last_price FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);5. 其他函数
1. NTH_VALUE(expr,n)函数
NTH_VALUE(expr,n)函数返回第n个expr的值。
举例:查询goods数据表中排名第2和第3的价格信息。
SELECT id, category, NAME, price,NTH_VALUE(price,2) OVER w AS second_price, NTH_VALUE(price,3) OVER w AS third_price FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);2.NTILE(n)函数
NTILE(n)函数将分区中的有序数据分为n个桶,记录桶编号。
举例:将goods表中的商品按照价格分为3组。
SELECT NTILE(3) OVER w AS nt,id, category, NAME, price FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);新特性2:公用表表达式
1 普通公用表表达式
普通公用表表达式的语法结构是:
WITH CTE名称
AS (子查询)
SELECT|DELETE|UPDATE 语句;普通公用表表达式类似于子查询,不过,跟子查询不同的是,它可以被多次引用,而且可以被其他的普 通公用表表达式所引用。
举例:查询员工所在的部门的详细信息。
SELECT * FROM departments WHERE department_id IN (SELECT DISTINCT department_id FROM employees );WITH emp_dept_id AS (SELECT DISTINCT department_id FROM employees) SELECT * FROM departments d JOIN emp_dept_id e ON d.department_id = e.department_id;2 递归公用表表达式
递归公用表表达式也是一种公用表表达式,只不过,除了普通公用表表达式的特点以外,它还有自己的 特点,就是可以调用自己。它的语法结构是:
WITH RECURSIVE
CTE名称 AS (子查询)
SELECT|DELETE|UPDATE 语句;递归公用表表达式由 2 部分组成,分别是种子查询和递归查询,中间通过关键字 UNION [ALL]进行连接。 这里的种子查询,意思就是获得递归的初始值。这个查询只会运行一次,以创建初始数据集,之后递归 查询会一直执行,直到没有任何新的查询数据产生,递归返回。
案例:针对于我们常用的employees表,包含employee_id,last_name和manager_id三个字段。如果a是b 的管理者,那么,我们可以把b叫做a的下属,如果同时b又是c的管理者,那么c就是b的下属,是a的下下 属。
代码实现:
WITH RECURSIVE cte
AS
(
SELECT employee_id,last_name,manager_id,1 AS n FROM employees WHERE employee_id = 100
-- 种子查询,找到第一代领导
UNION ALL
SELECT a.employee_id,a.last_name,a.manager_id,n+1 FROM employees AS a JOIN cte
ON (a.manager_id = cte.employee_id) -- 递归查询,找出以递归公用表表达式的人为领导的人
)
SELECT employee_id,last_name FROM cte WHERE n >= 3;


