查看自己的显卡配置
nvidia-smi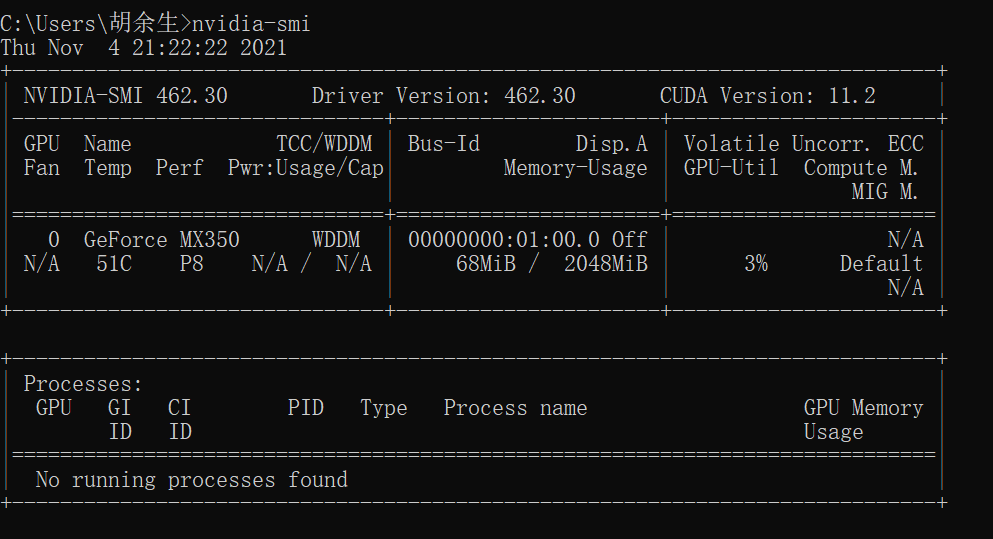
pytorch中
dir() :打开看见
help() : 说明书
dir(torch) 查看torch分隔区,我的理解就是包
help(torch.cuda.is_available) 查看 cuda.is_available 用法
pytorch中获取数据方法
dataset:提供一种放肆区获取数据以及label
- 如何获取每一个数据及其label
- 告诉我们总共有多少数据
dataloader:为网络提供不同的数据形式
python中特殊方法名称__getitem__和__add__和__len__
一个类可以通过定义具有特殊名称的方法来实现由特殊语法所引发的特定操作 (例如算术运算或下标与切片)。这是 Python 实现 操作符重载的方式,允许每个类自行定义基于操作符的特定行为。例如,如果一个类定义了名为 __getitem__(item) 的方法,并且 x 为该类的一个实例,则 x[i] 基本就等同于 x.__getitem__(i)。除此之外还有__len_()专有方法,则len(x)就等同于x.__len__(x);
__add__()专有方法,则x+other就等同于x.__add__(x,other),操作符重载
-> 'ConcatDataset[T_co]'指明返回类型
->常常出现在python函数定义的函数名后面,为函数添加元数据,描述函数的返回类型,从而方便开发人员使用。用 tensorboard 进行可视化操作
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
#writer.add_image()
for i in range(100):
writer.add_scalar("y=x",i,i)
writer.close()
打开 tensorboard 生成的可视化文件
tensorboard --logdir=logs更改生成可视化端口号
tensorboard --logdir=logs --port=端口号 #自己要改的端口号Python中的*args和**kwargs
首先*args必须放在**kwargs前面,*args用于传入可变长度的参数,**kwargs是将可变的关键字参数的字典传给函数实参,同样参数列表长度可以为0或为其他值
class person:
def __call__(self, *args, **kwargs):
for i in range(len(args)):
print("__call__"+"hello",args[i])
def hello(self,name):
print("hello"+name)
person = person()
person(1,2,3,4,5)
结果:
__call__hello 1
__call__hello 2
__call__hello 3
__call__hello 4
__call__hello 5class person:
def __call__(self, *args, **kwargs):
for i in kwargs.keys():
print("__call__"+"hello",kwargs.get(i))
def hello(self,name):
print("hello"+name)
person = person()
person(k1=1,k2=2,k3=3)
结果:
__call__hello 1
__call__hello 2
__call__hello 3args和kwargs不仅可以在函数定义中使用,还可以在函数调用中使用。在调用时使用就相当于pack(打包)和unpack(解包),类似于元组的打包和解包。
class person:
def __call__(self, arg1,arg2,arg3):
print(arg1)
print(arg2)
print(arg3)
def hello(self,name):
print("hello"+name)
person = person()
we = [1,2,3]
person(*we)
结果:
1
2
3class person:
def __call__(self, arg1,arg2,arg3):
print(arg1)
print(arg2)
print(arg3)
def hello(self,name):
print("hello"+name)
person = person()
we={"arg1":1,"arg2":2,"arg3":3}
person(**we)
结果:
1
2
3
注意:we中的key必须与函数中的arg1参数相同,不然会报错torchvision中datase和DataLoader
torchvision中dataset用于读取官网存在的数据集
torchvision中DataLoader用于加载数据集设置batch_size等
DataLoader不支持索引,所以可以用iter迭代器访问
DataLoader不支持索引,所以可以用iter迭代器访问
we = iter(test_load)
img , target = next(we)
print(img.shape,target)
img , target = next(we)
print(img.shape,target)
或者for data in DataLoader来进行访问
也可以枚举迭代器进行访问
for step,data in enumerate(iter):
imgs , target = data重写了forward函数,we(x),是调用了父类的__call__方法,也就是we.__call__(x)
class TestModel(nn.Module):
def __init__(self):
self.we1 = 1
super().__init__()
def forward(self,input):
output = input+1
return output
we = TestModel()
x = torch.tensor(1.0)
print(we(x))
'''
在python里,函数明和变量名字不可以一样,self.函数,self.变量都可以调用,如果一样会导致程序判断不出来是变量还是函数名,在上述代码中,重写了forward函数,we(x),是调用了父类的__call__方法,该方法里调用了forward函数,也可以这样 we.forward(x)调用forward函数,we(x)就等于we.__call__(x)
'''是时候总结一波自己遇到的魔法方法了
__get__():类中实现这个方法叫做描述器(set、delete)
class A:
def __init__(self):
print('执行__init__方法')
def __get__(self, instance, owner):
print('执行__get__方法')
class B:
a = A()
b = B() # 返回:执行__init__方法 解读:实例化只执行__init__方法,不调用 __get__方法
c = b.a # 返回:执行__get__方法 解读:A类作为B类的属性调用时,执行__get__方法
__getitem__(item):list[1]、list[1:2:2] 切片或索引 自动执行
__setitem__(item):list[1]=‘123’ 赋值 自动执行
__delitem__(item):del list[1] 删除值 自动执行
__call__():告诉你类对象也可以当作函数来调用,一般叫【函数式调用】。
__str__() :print(对象) 自动执行
__dict__():类名.dict,自动调用,对象中封装的所有成员通过字典形式返回
__doc__():类名.doc 时,自动调用,返回类都注释信息
__len__():使用len()函数时,自动调用
__add__():使用加号时,自动调用
__iter__():可迭代对象,for循环时 自动执行
__len_():返回长度,使用len()时自动调用
如果类中有__iter__方法,就是可迭代对象
对象.iter()的返回值是迭代器
。。。。。。待续conv2D表示是二维的,1D表示1维的,图片是二维的,一个向量是一维的
torch.nn和torch.nn.function的关系,torch.nn是torch.nn.function的封装
CONV2D输入与输出shape关系官方计算公式
计算输入输出公式

ceiling 和 floor模式
floor模式向下取整,ceiling向上取整
pytorch保存模型的几种方法
import torch
import torchvision
vgg16 = torchvision.models.vgg16(False)
#保存方式1 保存模型结构和模型参数
torch.save(vgg16,"vgg16_method1.pth")
#保存方式2 > 参数保存成字典形式,只保留了参数,而没有模型结构(官方推荐)
torch.save(vgg16.state_dict(),"vgg16_model2.pth")
model = torch.load("net_method1.pth")import torch
from torch import nn
'''#保存方式1 > 加载模型
import torchvision
from torch import nn
model = torch.load("vgg16_method1.pth")
#保存方式2 > 加载模型
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
#model = vgg16.load_state_dict()
'''
#陷阱
'''class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3,64,3)
def forward(self,input):
x = self.conv1(input)
return x
net = Net()
torch.save(net,"net_method1.pth")'''
#方式1保存方式陷阱,必须将模型原始的类放入py文件,否则加载不出来,如果是官方的模型不用写类,就是能够让加载模型的方法能够访问到模型的定义方式
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3,64,3)
def forward(self,input):
x = self.conv1(input)
return x
model = torch.load("net_method1.pth")
item
在torch中将
import torch
a = torch.tensor(5)
print(a)
print(a.item())
结果:
tensor(5)
5用pytorch写一个整体训练套路
#model.py文件
import torch
from torch import nn
from torch.nn import Sequential
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.model = Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,input):
x = self.model(input)
return x
#进行测试
if __name__ == '__main__':
net = Net()
input = torch.ones((64,3,32,32))
output = net(input)
print(output.shape)import torchvision
from torch.utils.tensorboard import SummaryWriter
from taolu_model import *
#准备数据集
from torch import nn
from torch.nn import Sequential
from torch.utils.data import DataLoader
train_data = torchvision.datasets.CIFAR10(root="dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集长度:{}".format(train_data_size))
print("训练数据集长度:{}".format(test_data_size))
#利用dataloader加载数据
train_data_loader = DataLoader(train_data,batch_size=64)
test_data_loader = DataLoader(test_data,batch_size=64)
#创建网络
net = Net()
#损失函数
loss_fn = nn.CrossEntropyLoss()
#优化器
#learn_rate = 0.01
learn_rate = 1e-2
optimizer = torch.optim.SGD(net.parameters(),lr=learn_rate)
#训练次数
rotal_train_step = 0
#测试次数
rotal_test_step = 0
#训练次数
epoch = 10
#添加tensorboard
writer = SummaryWriter("taolu")
for i in range(epoch):
print("————第{}轮训练开始————".format(i))
#训练步骤开始
net.train() #设置网络为train模式,只对dropout和normalization层有用
for data in train_data_loader:
imgs,target = data
output = net(imgs)
loss = loss_fn(output,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
rotal_train_step = rotal_train_step + 1
if(rotal_train_step%100==0):
print(rotal_train_step)
writer.add_scalar("train_loss",loss.item(),rotal_train_step)
print("训练次数:{},loss{}".format(rotal_train_step,loss))
net.eval()#设置网络为验证模式,只对dropout和normalization层有用
#测试步骤开始,无梯度
total_test_loss = 0
total_test_acc = 0
with torch.no_grad():
for data in test_data_loader:
imgs,target = data
output = net(imgs)
loss = loss_fn(output,target)
total_test_loss = total_test_loss + loss.item()
accury = (output.argmax(1) == target).sum()
total_test_acc = total_test_acc + accury
writer.add_scalar("test_loss", total_test_loss, rotal_test_step)
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体正确率:{}".format(total_test_acc/test_data_size))
writer.add_scalar("测试正确率",total_test_acc/test_data_size,i)
torch.save(net,"net_{}.pth".format(i))
writer.close()
outputs.argmax(0)
参数为0竖着比,参数为1横着比
import torch
outputs = torch.tensor([[0.1,0.2],[0.5,0.1]])
print(outputs.argmax(0))
#结果
tensor([1, 0])import torch
outputs = torch.tensor([[0.8,0.2],[0.2,0.8]])
print(outputs.argmax(1))
#结果
tensor([0, 1])调用GPU训练pytorch网络 方式1
找到:
网络模型
数据(输入,标注)
损失函数
调用他们的 .cuda() 方法
net = net.cuda()
loss_fn = loss_fn.cuda()
imgs = imgs.cuda()
target = target.cuda()
#其中网络和损失函数不需要另外赋值,赋值也没有问题,数据必须要另外赋值调用GPU训练pytorch网络 方式2
找到:
网络模型
数据(输入,标注)
损失函数
调用他们的 .to(device) 方法 device = torch.device("cpu") #在cpu上
device = torch.device("cuda") #在gpu上
device = torch.device("cuda:0") #在第一张显卡上
device = torch.device("cuda:1") #在第二张显卡上net = net.to(device)
loss_fn = loss_fn.to(device)
imgs = imgs.to(device)
target = target.to(device)
#其中网络和损失函数不需要另外赋值,赋值也没有问题,数据必须要另外赋值语法简写:cuda可用选用cuda否则选用cpu(GPU训练方式2更加常用)
device = torch.device("cuda" if torch.cuda.is_available else "cpu")GPU上训练的模型cpu上运行
model = torch.load("net_782.pth",map_location=torch.device("cpu"))一个测试流程
import torch
import torchvision
from PIL import Image
from torch import nn
from torch.nn import Sequential
image = Image.open(r'D:\pytorchstudy\data\练手数据集\train\ants_image\0013035.jpg')
image = image.convert('RGB') #如果图片是png会将透明度通道去掉只保留RGB颜色通道
print(image)
transform = torchvision.transforms.Compose([
torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()
])
image = transform(image)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.model = Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,input):
x = self.model(input)
return x
model = torch.load("net_782.pth",map_location=torch.device("cpu"))
print(model)
image = torch.reshape(image,[1,3,32,32])
model.eval()
with torch.no_grad(): #去掉梯度,节省内存,预测不需要更新梯度
output = model(image)
print(output.argmax(1)) #输出预测概率最大的类别完结撒花!!!



